
第一步:初步实现中断处理程序 #
理论 #
1. 什么是中断?为什么需要它? #
从字面上看,中断就是“打断”处理器当前正在执行的任务,让它转而去处理一个更紧急的事件,处理完毕后再返回到原来的地方继续执行。
你可以把它想象成你在专心写代码(当前任务),突然你的手机响了(中断事件)。你会:
- 保存当前状态:记住你代码写到了哪一行,思路是什么。
- 处理中断:接听电话。
- 恢复状态:挂断电话后,回到电脑前,根据刚才的记忆继续写代码。
操作系统中的中断也是如此,它主要处理以下三类事件:
- 外部中断 (External Interrupt):来自硬件设备的信号。例如,你按下键盘上的一个键,或者网卡接收到了一个数据包,这些硬件都需要通知CPU来处理。
- 异常 (Exception):在执行指令时由CPU内部产生的错误。例如,程序试图访问一个不存在的内存地址(缺页异常),或者执行了一条非法的指令。
- 系统调用 (System Call):用户程序主动请求操作系统提供服务。例如,程序需要读取文件或在屏幕上显示文字,它不能直接操作硬件,必须通过一个特殊指令(在我们的实验中是
int 0x80)请求内核代为完成。这是一种主动的、预期的中断,所以也称为陷阱 (Trap)。
为了区分不同的中断来源,i386架构为每个中断分配了一个唯一的8位无符号整数(0-255),我们称之为中断号或中断向量。
0 ~ 31:由CPU保留,用于处理异常,例如中断号14是缺页异常。32 ~ 47:通常分配给外部硬件设备,例如时钟、键盘等。48 ~ 255:可由操作系统自由使用,我们遵循Linux的惯例,使用0x80 (128)作为系统调用的中断号。
2. 硬件如何响应中断?—— 中断响应机制 #
当一个中断发生时,CPU(硬件)会自动执行一套固定的流程来响应它。这套流程不依赖于操作系统,是处理器设计的一部分。在i386架构下,这个过程的核心是中断描述符表 (IDT, Interrupt Descriptor Table)。它是一个存放在内存中的大数组。数组中的每一个元素都描述了一个中断的处理方式,特别是中断处理程序的入口地址。CPU通过一个特殊的寄存器 IDTR 来找到这个表在内存中的起始地址和大小。
IDT数组中的每个元素就是一个“门描述符”。它告诉CPU关于某个特定中断的所有信息。它的结构如下:
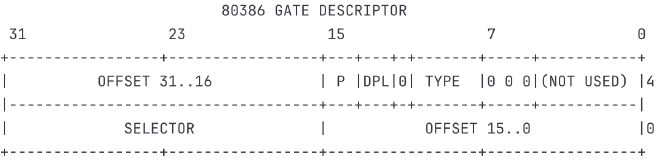
OFFSET和SELECTOR:这两个字段共同组成了中断处理程序的入口地址。上一篇笔记已经提到过,在保护模式下,一个(逻辑)地址由 段选择子 (SELECTOR) 和 段内偏移 (OFFSET) 组成,分别加载到CS(代码段寄存器) 和EIP(指令指针寄存器) 中。P(Present Bit):有效位。如果为1,表示该门描述符有效;如果为0,则无效。DPL(Descriptor Privilege Level):描述符特权级。这个字段用于安全检查。DPL=0:表示只有内核代码(最高权限)才能访问。用户程序不能通过int指令主动触发这个中断。DPL=3:表示允许用户程序(最低权限)通过int指令主动触发。我们的系统调用中断(0x80)就需要设置为3。- 注意:这个权限检查只对
int指令这样的软件中断有效。对于硬件中断和异常,CPU会忽略DPL检查,强制执行。
TYPE:门的类型。0xE- 中断门 (Interrupt Gate):当CPU通过中断门进入中断处理程序时,会自动清除EFLAGS寄存器的IF位,即关中断。这可以防止在处理一个中断时被其他外部中断打扰,简化了操作系统早期阶段的设计。外部中断通常使用这种门。0xF- 陷阱门 (Trap Gate):通过陷阱门进入时,不会改变IF位的状态。系统调用和异常通常使用这种门,因为有时在处理过程中可能需要响应其他中断。- 在我们的实验中,为了简化设计,所有门都统一使用中断门。
硬件中断响应的完整步骤 #
- 从
IDTR中读取IDT的基地址。 - 使用收到的中断号作为索引,在IDT中定位到对应的门描述符。
- 进行权限检查(仅针对软件中断)。
- 从门描述符中取出
SELECTOR和OFFSET,确定中断处理程序的入口地址。 - 在栈上依次压入:
EFLAGS寄存器、CS寄存器、EIP寄存器。EIP的值是中断发生时下一条将要执行的指令地址,这样iret指令才能正确返回。
- 对于某些特定的异常(如缺页),硬件还会额外压入一个32位的错误码 (Error Code),提供关于异常的更多信息。
- 如果门描述符是中断门,则清除
EFLAGS寄存器的IF位(关中断)。 - 将门描述符中的
SELECTOR和OFFSET分别加载到CS和EIP寄存器,跳转到中断处理程序开始执行。
核心思想:中断响应过程非常类似于一次特殊的、由硬件控制的函数调用。它将返回地址(CS:EIP)和处理器状态(EFLAGS)保存在栈上,然后跳转到处理函数。中断处理结束后,通过
iret指令从栈上恢复这些值,实现返回。
3. 软件如何处理中断?—— 中断处理流程 #
硬件完成了跳转,接下来的工作就全部交给我们的操作系统软件了。我们的处理代码位于 kernel/src/trap.S。
3.1 入口点与统一处理 (irqX -> trap)
#
虽然i386硬件支持为每个中断号设置一个完全不同的处理函数,但在实际操作系统中,中断处理的某些步骤是相同的(如保存现场)。为了避免代码重复,我们采用了一个通用设计:
- 为每一个需要处理的中断号(如
irq0,irq1,irq32…)定义一个极小的汇编入口。 - 这些入口只做两件事:
- 如果硬件没压入错误码,就压入一个“伪错误码”
0,维持结构的一致性。 - 压入中断号。
- 如果硬件没压入错误码,就压入一个“伪错误码”
- 然后,全部跳转(
jmp)到一个公共的处理函数trap。
为什么要压“伪错误码”?
某些异常(如8, 10, 11, 12, 13, 14)硬件会自动压入错误码,而其他中断不会。为了让所有中断发生后,栈的结构都保持一致,我们为那些硬件不压错误码的中断手动压入一个0。这样,后续处理代码就可以用统一的方式访问栈上的数据,大大简化了设计。
来看例子:
# 中断1,硬件不压错误码,我们手动压0,再压入中断号1
.globl irq1; irq1: push $0; push $1; jmp trap;
# 中断14(缺页),硬件已压错误码,我们只需压入中断号14
.globl irq14; irq14: ; push $14; jmp trap;
3.2 构建中断上下文 (Context) #
进入 trap 标签后,我们需要为即将调用的C语言处理函数 irq_handle 准备一个完整的现场环境。这个完整的现场信息集合,我们称之为中断上下文 (Context)。
构建过程如下:
- 保存通用寄存器:依次压入
eax,ebx,ecx,edx,esi,edi,ebp。 - 保存段寄存器:保存
ds(es通常与ds相同,一并处理)。 - 切换到内核数据段:将
ds和es设置为内核的数据段选择子 (KSEL(SEG_KDATA)),确保后续的内存访问都在内核空间中,安全可靠。
至此,栈上的布局从高地址到低地址依次是:
| 栈内容 (从高到低) | 压栈者 | 描述 |
|---|---|---|
EFLAGS, CS, EIP |
硬件 | 中断前的状态和返回地址 |
error_code (或伪错误码0) |
硬件/软件 | 统一栈帧结构 |
irq (中断号) |
软件 | 标识中断来源 |
eax, ebx, ecx, … ebp |
软件 | 通用寄存器现场 |
ds, es |
软件 | 段寄存器现场 |
这个保存在栈上的完整结构,就是一个 Context 结构体。
3.3 调用C函数 (irq_handle)
#
如何将这个庞大的 Context 结构体传递给C函数 irq_handle 呢?如果定义一个有十几个参数的函数会非常笨拙。
巧妙的方法是:传递一个指向这个结构体的指针。
由于 esp 寄存器此刻正指向栈顶,也就是 Context 结构体的起始位置,我们只需在调用 irq_handle 前执行 pushl %esp,就相当于把 Context 的地址作为参数压栈了。
trap:
pushl %eax
... # 保存所有寄存器
pushl %esp # 将指向Context的指针作为参数压栈
call irq_handle # 调用C函数
.L0:
jmp .L0 # irq_handle不应返回,这里是死循环以防万一
3.4 C语言分发与处理 (irq_handle)
#
irq_handle 函数在C语言层面进行中断的分发。它接收一个 Context* 指针,通过这个指针可以轻松访问到之前保存的所有寄存器和信息,特别是中断号。
void irq_handle(Context *ctx) {
if (ctx->irq <= 16) {
// just ignore me now, usage is in Lab1-6
exception_debug_handler(ctx);
}
switch (ctx->irq) {
// TODO: WEEK2 handle syscall
// TODO: WEEK2 handle serial and timer
// TODO: WEEK3-virtual-memory: page fault
// TODO: WEEK4-process-api: schedule
default: {
// printf("Get error irq %d\n", ctx->irq);
assert(ctx->irq >= T_IRQ0 && ctx->irq < T_IRQ0 + NR_INTR);
}
}
irq_iret(ctx);
}q_iret(ctx);
}
3.5 中断返回 (irq_iret)
#
当C语言层面的处理完成后,它会调用汇编函数 irq_iret 来执行返回流程。irq_iret 也接收 Context* 指针作为参数。
- 恢复ESP:
irq_iret首先从参数中获取Context的地址,并将esp寄存器直接设置为这个地址。这就解决了“ESP如何恢复”的问题。一旦esp指向了Context的开头,我们就可以开始弹栈了。 - 恢复寄存器:按照与压栈相反的顺序,用
pop指令恢复ds,es和所有通用寄存器。 - 跳过错误码和中断号:用
addl $8, %esp指令,让esp跳过栈上的错误码和中断号。 - 执行
iret指令:这是中断返回的专用指令。它会自动从栈上弹出EIP,CS,EFLAGS,恢复到中断发生前的状态,程序从原来的地方继续执行。
4. 你的任务 #
现在,你需要根据以上原理,完成以下任务:
-
任务一:修正
Context结构体定义- 文件:
kernel/include/cte.h - 目标:
Context结构体的成员顺序必须与trap.S中压栈的顺序完全相反。 - 原因:栈是向低地址增长的(后压入的元素地址更低),而C语言结构体的成员是按地址从低到高排列的。因此,
Context结构体的第一个成员应该对应最后压栈的ds,最后一个成员应该对应最先由硬件压栈的EFLAGS。 - 请仔细核对
trap.S中的压栈顺序,正确排列Context的成员。
- 文件:
-
任务二:启用中断初始化
- 文件:
kernel/src/main.c - 目标:找到并取消
init_cte()函数调用前的注释。 - 作用:
init_cte()函数负责初始化IDT,将我们定义的中断处理程序入口地址填入表中。如果不执行这个函数,IDT就是无效的,整个中断机制将无法工作。
- 文件:
-
重要提示
- 由于你修改了头文件 (
.h),为了确保所有引用它的源文件都能重新编译,请在修改后务必先执行make clean,然后再执行make进行编译。
- 由于你修改了头文件 (
第二步:实现系统调用接口 #
在上一阶段,我们搭建了中断处理的骨架。现在,我们要利用这个骨架来实现操作系统最核心的功能之一:系统调用 (System Call)。这一步同样可以划分用户和操作系统的职责,界限?当然是那条已经提到了很多次的中断指令 int $0x80。
复习一下:什么是系统调用?
系统调用就是用户程序与操作系统内核之间的“柜台”。用户程序运行在低权限的用户态,很多操作(如读写文件、访问硬件)是被禁止的。当它需要执行这些操作时,就必须通过一个特殊的方式请求高权限的内核态来帮忙完成。这个请求的过程,就是系统调用。
与之前处理的异常(如缺页)不同,系统调用有三个关键特点:
- 主动性:它是用户程序通过执行一条特定指令(在我们的实验中是
int $0x80)主动触发的。- 目的性:它不是一个错误,而是一次有明确目的的请求。
- 约定性:用户程序和操作系统之间必须有一套严格的“沟通协议”,规定如何传递请求类型、参数以及如何返回结果。
2. 用户程序的视角:如何发起一次系统调用 #
2.1 寄存器约定 (ABI) #
**应用二进制接口 (Application Binary Interface, ABI)**是一套关于如何使用寄存器的约定。我们的操作系统规定如下:
EAX寄存器: 存放 系统调用号 (System Call Number)。这是一个整数,用来告诉操作系统“我要办理哪项业务”。例如,0号代表write(写入/打印),1号代表read(读取)。这些号码定义在lib/include/sysnum.h文件中。EBX,ECX,EDX,ESI,EDI寄存器: 按顺序存放系统调用的最多5个参数。例如,调用write时,EBX可能放文件描述符,ECX放字符串地址,EDX放字符串长度。EAX寄存器 (返回时): 系统调用执行完毕后,操作系统会把返回值放回EAX寄存器。用户程序通过读取EAX的值来获取操作结果。
2.2 从C语言到 int $0x80:syscall 封装
#
在C语言里,我们无法直接写 int $0x80。因此,我们提供了一个C函数来“封装”这个过程。请看 user/ulib/syscall.c 中的代码:
// syscall 函数:所有系统调用的底层封装
int syscall(int num,
size_t arg1, size_t arg2, size_t arg3, size_t arg4, size_t arg5) {
int ret; // 用于接收返回值的C变量
// 使用内联汇编
asm volatile (
"int $0x80" // 核心指令:执行128号中断,即系统调用
: "=a"(ret) // 1. 输出部分:告诉编译器,执行完汇编后,把 EAX 寄存器 ("a") 的值,
// 写入到 C 变量 ret 中。
: "a"(num), "b"(arg1), "c"(arg2), "d"(arg3), "S"(arg4), "D"(arg5)
// 2. 输入部分:告诉编译器,在执行汇编前,
// - 把 C 变量 num 的值放入 EAX 寄存器 ("a")
// - 把 C 变量 arg1 的值放入 EBX 寄存器 ("b")
// - 把 C 变量 arg2 的值放入 ECX 寄存器 ("c")
// - 把 C 变量 arg3 的值放入 EDX 寄存器 ("d")
// - 把 C 变量 arg4 的值放入 ESI 寄存器 ("S")
// - 把 C 变量 arg5 的值放入 EDI 寄存器 ("D")
);
return ret; // 将从 EAX 获取的结果返回给调用者
}
// write 函数:一个具体的系统调用封装
int write(int fd, const void *buf, size_t count) {
// 调用底层 syscall 函数,传入 write 的系统调用号 (SYS_write) 和三个参数
return (int)syscall(SYS_write, (size_t)fd, (size_t)buf, (size_t)count, 0, 0);
}
这段代码完美地实现了我们之前约定的协议。write 函数调用 syscall,syscall 函数通过内联汇编将参数和系统调用号安放到正确的寄存器中,然后执行 int $0x80 陷入内核。当中断返回后,再从 EAX 中取出返回值。
补充知识:谁来保存寄存器?
你可能会问:在把
num,arg1等值放入寄存器之前,不需要保存这些寄存器原来的值吗?答案是:需要,但这部分工作由C编译器和调用约定(Calling Convention)来处理了。在x86架构中,寄存器被分为两类:
- 调用者保存 (Caller-saved):像
EAX,ECX,EDX。如果一个函数(调用者)在调用另一个函数后还想使用这些寄存器里的值,它必须自己负责在调用前保存它们。- 被调用者保存 (Callee-saved):像
EBX,ESI,EDI。如果被调用的函数想使用这些寄存器,它必须在用之前先保存好,并在返回前恢复它们。我们写的内联汇编被编译器视为一个“被调用的函数”。编译器知道这个“函数”会修改
EAX,EBX等寄存器,所以在生成最终的汇编代码时,它会自动在asm volatile前后插入保存和恢复指令,我们无需操心。
3. 操作系统的视角:如何处理一次系统调用 #
当用户程序执行 int $0x80 后,CPU的控制权就交给了操作系统。
3.1 统一的入口,不同的处理 #
int $0x80 本质上就是一次中断号为128的中断。所以,它的处理流程和我们之前学的完全一样:
- 硬件响应,压入
EFLAGS,CS,EIP。 - 跳转到IDT中128号门描述符指向的地址,也就是
kernel/src/trap.S中的irq128。 irq128压入伪错误码0和中断号128,然后跳转到trap。trap保存所有通用寄存器,构建好完整的中断上下文 (Context)。- 最后,调用C语言函数
irq_handle。
此时,中断上下文 (Context) 里的寄存器值,正是用户程序在调用 syscall 时精心准备好的!
3.2 分发请求:irq_handle
#
irq_handle 函数是负责统一调度所有中断。它的工作就是查看中断号,然后把请求派发给相应的处理函数。对于系统调用,我们需要在这里添加逻辑:
// 文件:kernel/src/cte.c
void irq_handle(Context *ctx) {
// ... 其他中断处理 ...
switch (ctx->irq) {
// 当中断号是 EX_SYSCALL (即128) 时
case EX_SYSCALL: {
// 调用专门处理系统调用的函数 do_syscall
// 把整个中断上下文指针传过去,因为所有信息都在里面
do_syscall(ctx);
break;
}
// ... 其他 case ...
}
// 最终调用 irq_iret 返回
irq_iret(ctx);
}
3.3 执行请求:do_syscall
#
do_syscall 函数统一负责所有系统调用的处理。它负责从上下文中解析出用户的请求,调用相应的内核功能,然后将结果写回上下文。
// 文件:kernel/src/syscall.c
// syscall_handle 是一个函数指针数组,存放了所有 sys_* 函数的地址
static const syshandle_t syscall_handle[] = {
[SYS_write] = sys_write,
[SYS_read] = sys_read,
// ... 其他系统调用处理函数
};
void do_syscall(Context *ctx) {
// 1. 解析请求:从中断上下文中取出系统调用号和参数
// 这正是用户程序通过寄存器传进来的值
int sysnum = ctx->eax;
uint32_t arg1 = ctx->ebx;
uint32_t arg2 = ctx->ecx;
uint32_t arg3 = ctx->edx;
uint32_t arg4 = ctx->esi;
uint32_t arg5 = ctx->edi;
int res; // 用于存放处理结果
// 2. 执行请求
if (sysnum >= 0 && sysnum < NR_SYS && syscall_handle[sysnum]) {
// 如果系统调用合法,就从数组中取出对应的处理函数指针并调用,同时存储处理结果
res = syscall_handle[sysnum](arg1, arg2, arg3, arg4, arg5);
} else {
// 非法的系统调用,返回-1
res = -1;
}
// 3. 写回结果:将处理结果放入上下文的 eax 成员中
// 当中断返回时,这个值会被恢复到 EAX 寄存器,用户程序就能收到了
ctx->eax = res;
}
补充知识:为什么参数类型不匹配也能调用?
你可能注意到
sys_write的原型和do_syscall里调用的形式并不完全匹配(比如参数数量)。这之所以能工作,得益于i386的C语言调用约定(cdecl):
- 参数从右到左压栈:调用者负责把所有5个参数压入栈。
- 被调用者按需取用:
sys_write函数知道自己只需要3个参数,所以它只会从栈上取前3个。后面的参数虽然在栈上,但它不会去碰。- 调用者清理栈:当
sys_write返回后,是do_syscall(调用者)负责把当初压入的5个参数全部从栈上清理掉。只要所有参数和返回值都是32位大小,这种机制就能确保栈的平衡,使得调用可以成功。
补充知识:内核访问用户内存
sys_write函数会直接使用用户程序传来的buf指针。为什么内核可以直接访问用户空间的地址呢?因为在发生中断后,操作系统虽然获得了CPU控制权,但内存的映射关系(页表)还没有切换。当前有效的页表仍然是属于那个用户程序的。因此,内核可以像用户程序一样访问它的地址空间。这是一个便利的设计,但也存在安全风险:如果用户程序传来一个恶意的指针,指向了内核自身的内存区域怎么办?一个健壮的操作系统必须在这里进行严格的地址检查,确保指针指向的是合法的用户空间内存。在我们的实验中,为了简化,暂时忽略了这个问题。
第三步:实现真正的中断机制——内核栈与任务状态段 (TSS) #
在前两个阶段,我们成功地建立了中断和系统调用的基本框架。然而,这个框架存在一个严重的安全和稳定性漏洞。本阶段,我们将通过引入i386架构提供的真正中断机制来修复它。
理论:用户态的栈指针并不可信 #
1. 问题重现:一个能让系统崩溃的用户程序 #
我们当前对中断处理的实现,建立在一个致命的假设上:我们信任用户程序提供的栈指针 (ESP) 是有效的。让我们看看当用户程序不怀好意时会发生什么。
请看这个测试用例:user/src/phase2/systest.c
void test() {
// ...
asm volatile (
// ...
"movl $0xfffffffc, %%esp;" // 关键!在系统调用前,故意将ESP设置为一个无效地址
"int $0x80;" // 触发系统调用
// ...
);
// ...
}
这个程序在执行 int $0x80 之前,将栈指针 ESP 修改为了 0xfffffffc。这个地址通常是未映射或只读的,用户程序无权写入。
现在,我们来一步步追踪CPU(硬件)在看到 int $0x80 指令后的行为:
- 中断响应开始:CPU接收到128号中断,准备跳转到我们的内核处理程序。
- 第一次压栈(失败):根据中断响应机制,CPU需要将当前的
EFLAGS、CS和EIP寄存器的值压入栈中。它试图将EFLAGS写入ESP指向的地址,也就是0xfffffffc。 - 产生页错误异常 (#PF):由于
0xfffffffc是一个不可写的地址,内存管理单元 (MMU) 会立即阻止这次写入,并产生一个14号异常——页错误 (Page Fault)。 - 中断嵌套,尝试处理页错误:CPU暂停了对系统调用的处理,转而开始响应这个新的、更紧急的页错误异常。
- 第二次压栈(失败):为了处理页错误,CPU又需要将当前的(即发生页错误时的)
EFLAGS、CS、EIP以及一个错误码压栈。但是,此时的ESP仍然是那个错误的0xfffffffc!CPU再次尝试向这个无效地址写入,结果又产生了一个页错误。 - 产生双重故障异常 (#DF):当CPU在处理一个异常的过程中,又发生了第二个异常,它会放弃处理,转而产生一个8号异常——双重故障 (Double Fault)。这是系统出现严重问题的信号。
- 第三次压栈(失败):CPU现在尝试响应双重故障异常。它又一次需要压栈保存现场。不幸的是,
ESP依然是0xfffffffc。第三次向无效地址的写入尝试,导致了又一个异常。 - 三重故障 (Triple Fault) -> 系统重置:当CPU在处理双重故障的过程中再次发生异常,它会认为系统已经处于无法恢复的状态。此时,它会放弃所有治疗,直接触发三重故障,这会导致处理器立即重置 (Reset)。
在QEMU中,你会观察到整个模拟器直接退出。这个过程完全由硬件主导,我们的操作系统代码甚至没有机会运行一行。根本原因在于:在从用户态切换到内核态时,绝对不能信任用户程序提供的任何状态,尤其是栈指针 ESP。
2. 真正的中断响应机制:栈切换与TSS #
为了解决上述问题,i386架构提供了一套更完备的中断响应机制,其核心是在发生特权级变更时(例如从用户态切换到内核态),自动切换到一个由操作系统预先准备好的、安全可靠的内核栈 (Kernel Stack)。
这个机制依赖于一个关键的数据结构:任务状态段 (Task State Segment, TSS)。
- TSS是什么? TSS是一个特殊的段,被一个定义在GDT中的段描述符所描述。它保存了与一个“任务”相关的大量状态信息。在我们的操作系统中,我们不使用它来进行任务切换,但我们必须使用它来告知CPU内核栈的位置。
- TSS的关键字段:
ss0和esp0TSS结构体中有两个非常重要的字段:ss0:存放内核数据段的选择子。esp0:存放内核栈的栈顶地址。
现在,让我们看看引入TSS后,硬件中断响应的完整流程:
- 从IDTR中读出IDT的首地址。(不变)
- 根据中断号在IDT中进行索引,找到一个门描述符。(不变)
- 从门描述符上找到中断处理程序的入口地址。(不变)
- 新增的关键步骤:检查特权级并切换栈
- CPU检查当前代码段寄存器
CS的低两位,即CPL(当前特权级)。 - 如果CPL是用户态 (3),并且中断将要跳转到内核态 (0),CPU将执行一次自动的栈切换:
a. 从一个特殊寄存器
TR(Task Register) 中找到当前TSS的位置。 b. 从TSS中读取ss0和esp0的值。 c. 立即将CPU的SS和ESP寄存器设置为ss0和esp0的值。CPU现在已经切换到了内核栈! d. 在新的内核栈上,依次压入用户态的SS和ESP的旧值,以便将来能返回。
- CPU检查当前代码段寄存器
- 硬件依次将
EFLAGS,CS,EIP寄存器的值压入(现在的内核)栈。对于某些异常,还会再压栈一个错误码。(不变,但操作的栈变了) - 如果门描述符是中断门,清除EFLAGS的IF位。(不变)
- 跳转到中断处理程序的入口地址。(不变)
为了确保操作系统的绝对安全,硬件只在从不可信的用户态切换到可信的内核态这一个关键时刻,才会强制将栈指针切换到一个由内核预先指定的安全区域——内核栈。这样做是为了防止用户程序通过一个恶意的或损坏的栈指针来攻击内核。
一旦进入了内核态,操作系统就能保证栈指针的有效性,因此后续在内核中发生的中断嵌套(例如时钟中断打断了系统调用)就不再需要、也不能再进行栈切换了——如果每次嵌套都重置栈指针到同一个初始位置,那么后发生的中断就会覆盖掉先发生中断保存的现场信息,导致系统在返回时彻底混乱。
正确的做法是,只有第一次特权级提升时切换一次栈,后续的内核态中断则像普通函数调用一样,在当前栈的基础上继续压栈,这样才能利用栈的“后进先出”特性完美地处理中断的嵌套与返回。
有了这个机制,systest 的问题就解决了。当 int $0x80 发生时,CPU发现是从用户态进入内核态,会立刻丢弃 0xfffffffc 这个无效的 ESP,切换到我们在TSS里设置好的、绝对安全的内核栈顶,然后再进行后续的压栈操作。
相应的,iret 指令也变得更智能了。当它发现自己要从内核态返回到用户态时,它会自动从栈上弹出 ESP 和 SS,从而恢复用户栈。
注意,这个新增的步骤是完全由硬件自动完成的,而不是我们os的代码实现。那么,我们需要在os中做些什么来让硬件实现这个功能呢?
实践 #
任务3:更新中断上下文结构体 #
由于硬件现在会在内核栈上额外保存用户态的 ss 和 esp,我们也需要在 Context 结构体中为它们留出位置。修改头文件后,务必 make clean 再重新编译。
任务4:完成正确的用户态切换 #
继续考察这个新增的、由硬件执行的中断步骤,我们发现硬件会考察CS段的特权级是用户特权级。所以接下来要做的就是配合硬件——当os决定加载用户程序、转向用户态时,我们要真正实现一个 “转向用户态”例程,例程中要包含设置cs特权级操作。
例程要做的不止这个。想一想,转向用户态时,OS 还要做什么?肯定要修改 EIP,让它指向用户程序的入口地址。用户和内核使用不同的栈,所以还要设置一个用户栈地址,放入 ESP。总结一下,当os准备运行用户程序、内核准备转向用户态时,OS 需要
- 设置
CS为用户代码段选择子(特权级3)。 - 设置
EIP为用户程序的入口地址。 - 设置
ESP为用户栈顶地址。
所以,当os运行用户程序时,需要一个例程来做到这三点。那么我们需要单独搞一个enter_userstate来做到这一点吗?有什么现成的过程可以方便地一起修改这几个值呢?中断返回过程!中断返回时通过弹栈恢复中断上下文就可以修改这些值了。所以为了让os运行用户程序时进入用户态,我们“伪造”一次从内核到用户的中断返回,这次返回例程就是我们需要的 “转向用户态”例程。
- 操作:完成
kernel/src/loader.c中的load_user函数。该函数负责加载ELF文件,并初始化传入的ctx指针,使其成为一个可以启动用户程序的“初始上下文”。也就是说,它决定了我们这次“伪中断返回”的上下文!
任务5:在“实现中断”的前提下,完成正确的进程管理 #
回忆一下,我们week1是怎么进入一个新的进程?通过pcb中规定的entry入口点(顺便一提,这个entry由load_elf得到)。现在为了实现中断,必须换掉这个实践。
新的实践是:每个进程都要有一个内核栈和一个中断上下文(Context)。当os想运行一个进程时,先经过上文提到的load_user()初始化进程的上下文,然后调用 proc_run 函数。proc_run 函数会设置TSS,并调用 irq_iret(Context *ctx) 函数。该函数根据进程的上下文,进行“伪中断返回”,从而实现从内核态到用户态的切换。
-
操作1:在
kernel/include/proc.h中,找到proc_t结构体,取消ctx和kstack成员的注释,并删除不再需要的entry成员。 -
操作2:修改
kernel/src/proc.c中的init_proc和proc_alloc函数。-
init_procvoid init_proc() { // ... // 为0号进程(内核自身)分配内核栈,位置在内核内存的最高一页 pcb[0].kstack = (void *)(KER_MEM - PGSIZE); // 将0号进程的上下文指针指向其内核栈的底部 pcb[0].ctx = &pcb[0].kstack->ctx; // ... } -
proc_alloc(分配一个新的用户进程)proc_t *proc_alloc() { for (int i = 1; i < PROC_NUM; i++) { if (pcb[i].status == UNUSED) { // ... // 暂时让所有用户进程共享一个内核栈地址 // 这在多进程环境下是不对的(想一想,为什么),应该为每个进程分配独立的内核栈 pcb[i].kstack = (void *)(KER_MEM - (i + 1) * PGSIZE); // 修正为每个进程不同 pcb[i].ctx = &pcb[i].kstack->ctx; // ... return &pcb[i]; } } return NULL; }- 说明:
kstack_t是一个union,它巧妙地将一块内存(stack数组)和一个Context结构体(ctx)叠加在一起。这样,ctx就位于这块栈内存的末尾(高地址处),当我们将esp0指向栈顶(高地址)时,Context结构体正好在栈的底部(低地址处),方便我们访问。
- 说明:
-
-
操作3:修改
kernel/src/proc.c中的proc_run函数。void proc_run(proc_t *proc) { proc->status = RUNNING; curr = proc; // 设置TSS。告知CPU,当下次有中断从用户态进入内核态时, // 应该将ESP切换到当前进程的内核栈顶。 set_tss(KSEL(SEG_KDATA), (uint32_t)STACK_TOP(proc->kstack)); // 执行中断返回,这将根据proc->ctx中的内容, // 将CPU的控制权转移到用户态的用户程序入口。 irq_iret(proc->ctx); } -
操作2:相应地修改
kernel/src/main.c中的init_user_and_go函数。void init_user_and_go() { proc_t *proc = proc_alloc(); assert(proc); // 调用 load_user,注意第二个参数传入了 proc->ctx, // load_user 会填充这个上下文结构体。 assert(load_user(NULL, proc->ctx, "systest", NULL) == 0); // 运行进程 proc_run(proc); }
kstack_t是一个union,它巧妙地将一块内存(stack数组)和一个Context结构体(ctx)叠加在一起。这样,ctx就位于这块栈内存的末尾(高地址处),当我们将esp0指向栈顶(高地址)时,Context结构体正好在栈的底部(低地址处),方便我们访问。
完成以上所有步骤后,重新编译并运行,systest 样例现在应该能够顺利通过。int $0x80 触发的系统调用会因为栈切换机制而安全地进入内核,并成功执行。
第四步:处理外部中断 #
到目前为止,我们处理的中断(异常和系统调用)都源于CPU内部。现在,我们要处理来自计算机外部硬件的信号,这被称为外部中断。其处理流程与内部中断大同小异,都是利用我们已经建立的中断响应机制。
理论:外部中断的等待与处理 #
1. Polling vs. Interrupt: 一种更高效的等待方式 #
CPU有时候要等一个重要的事情完成,才能继续运行当前程序。有两种方法:
- 轮询 (Polling):每隔一段时间就询问“是否完成”,什么别的事也做不了。
- 中断 (Interrupt):CPU不用持续询问,等事情完成时再通知它。
在操作系统中,getchar 函数等待键盘输入时,如果写成这样:
// 轮询方式,效率极低
while (serial_has_data() == false) {
// 循环,不停地检查,浪费CPU
}
return serial_get_char();
这就是在“忙等”,CPU会100%空转,浪费了大量的计算资源和电力。外部中断机制就是那个“门铃”,它允许CPU在没有事件发生时“休息”或处理其他任务。
2. sti, hlt, cli: CPU的“开门-睡觉-关门”三连
#
为了实现高效等待,我们需要使用三条特殊的汇编指令:
sti(Set Interrupt Flag): 这条指令会将EFLAGS寄存器中的IF位置为1。它的作用是开启中断,告诉CPU:“我现在准备好接收外部硬件中断了”。如果IF位是0,大部分外部中断都会被CPU忽略。hlt(Halt): 这条指令会暂停CPU的执行,使其进入低功耗的“睡眠”状态。CPU会一直“睡”在这里,直到一个外部中断信号将它“唤醒”。cli(Clear Interrupt Flag): 这条指令会将IF位清零,即关闭中断。在我们的玩具操作系统中,内核代码的大部分流程都假设在关中断环境下运行,以避免并发执行带来的复杂性。因此,从中断中醒来后,我们通常会立即关中断,处理完事务再在需要时开启。
通过组合使用它们,我们可以将上面的忙等循环改造为高效的等待:
// 中断方式,高效
while (serial_has_data() == false) {
sti(); // 1. 开门:允许外部中断进来
hlt(); // 2. 睡觉:CPU暂停,等待中断
cli(); // 3. 关门:被唤醒后,立刻关中断,回到内核默认状态
}
return serial_get_char();
注意:为什么醒来后还要在
while循环里再次检查?因为唤醒CPU的可能是任何外部中断(比如接下来要讲的时钟中断),而不一定是我们正在等待的串口中断。所以醒来后必须重新检查条件,如果不是我们想要的事件,就继续“睡回笼觉”。
实践:完成外部中断代码 #
A. 启用用户程序的中断 #
首先,要让外部中断能够抵达CPU,用户程序必须在开中断的状态下运行。
- 操作: 修改
kernel/src/loader.c中的load_user函数。 - 细节: 将
ctx->eflags的初始值从0x002改为0x202。0x200这个比特位就是EFLAGS寄存器中的中断允许标志(IF)。设置为1后,当iret返回用户态时,CPU就会自动响应外部中断。
B. 处理串口中断 (键盘输入) #
- 操作 1: 修改
kernel/src/cte.c的irq_handle函数。添加一个case来处理串口中断。串口1的中断号是T_IRQ0 + IRQ_COM1(即32 + 4 = 36)。 - 操作 2: 修改
kernel/src/serial.c中的getchar函数,将原来的忙等循环替换为我们刚才讨论的sti(); hlt(); cli();高效等待模式。
C. 处理时钟中断 (系统计时) #
-
操作 1: 在
kernel/src/main.c的main函数中,取消init_timer();前的注释。这个函数会初始化硬件定时器,让它每隔0.01秒(一个tick)产生一次中断。 -
操作 2: 类似于串口中断,在
kernel/src/cte.c的irq_handle函数中,添加一个case来处理时钟中断。时钟的中断号是T_IRQ0 + IRQ_TIMER(即32 + 0 = 32)。// kernel/src/cte.c // ... case T_IRQ0 + IRQ_TIMER: timer_handle(ctx); // 调用已写好的时钟处理函数 break; // ...timer_handle的作用很简单,就是将一个全局变量ticks加一。
D. 实现 sleep 系统调用
#
有了系统时钟,我们就可以实现一个让程序暂停一段时间的系统调用。
- 操作: 实现
kernel/src/syscall.c中的sys_sleep函数。 - 逻辑:
- 调用
get_tick()获取当前的系统时间start_tick。 - 进入一个
while循环,循环条件是get_tick() < start_tick + ticks_to_sleep。 - 在循环体内,使用
sti(); hlt(); cli();让CPU休眠,等待下一次时钟中断唤醒。
- 调用
第五步:实现“终端”基础功能 #
现在我们的操作系统已经相当完备了。最后一步,我们来实现两个重要功能:向用户程序传递参数和**exec系统调用**,这将让我们能运行一个简单的shell。
理论 #
1. main(int argc, char *argv[]): 程序的参数
#
我们的os中用户程序可以暂时理解为由c编译出的elf。在C语言中,main函数的这两个参数用于接收命令行参数。
argc(argument count): 整数,表示参数的个数。argv(argument vector): 一个指向字符串的指针数组。argv[0]是程序名,argv[1]是第一个参数,以此类推。按照约定,argv[argc]必须是一个NULL指针,作为数组的结束标记。
我们的任务是,在启动用户程序之前,由操作系统在用户栈上构建好这个结构。
2. 在用户栈上构建参数 #
当 load_user 被调用时,我们需要在用户栈的最高地址处,从上到下依次放入:
- 所有参数字符串的实际内容 (例如
"hello","world")。 argv数组,这是一个指针数组,其中的每个元素指向上面那些字符串的地址。数组以一个NULL指针结尾。_start函数的参数:- 指向
argv数组起始地址的指针。 argc的值。
- 指向
- 一个为
_start函数准备的返回地址(虽然不会被用到,但栈帧结构需要它)。
最终,ESP寄存器将指向这个返回地址的位置。当用户程序开始执行时,它就能从栈上正确地获取argc和argv。
3. exec 系统调用的概念:原地替换
#
exec 是 “execute” 的缩写,但它的行为更像是 “replace”(替换)。
- 函数原型:
int exec(const char *path, char *const argv[]); - 功能:
- 找到路径为
path的可执行文件。 - 加载这个新程序,用它的代码、数据和全新的栈彻底替换掉当前正在运行的程序。
- 新程序以
argv作为其命令行参数开始执行。
- 找到路径为
- 独特的返回值:
- 如果成功:
exec永远不会返回。因为调用它的那个旧程序已经不复存在了,CPU的控制权已经完全交给了新程序。 - 如果失败 (例如,
path指定的文件不存在):exec会返回-1。旧程序会继续从调用exec的下一行代码开始执行。注意这里的失败发生在新程序替代之前,所以是能返回旧程序的。
- 如果成功:
这个“成功不返回”的特性是理解 exec 的关键。它不是像普通函数那样调用一个子程序然后返回,而是进行一次“单程旅行”,将当前进程变为一个全新的进程。
4. exec 的实现思路:重用启动流程
#
exec 看上去很神奇,但它的实现原理我们其实已经接触过了。回想一下我们是如何启动第一个用户程序的 (init_user_and_go 函数):
- 分配一个进程控制块 (
proc_t)。 - 调用
load_user函数,它会:- 从磁盘加载ELF文件。
- 创建一个用于“中断返回”的中断上下文 (
Context),其中包含了新程序的入口地址 (eip)、用户态的段寄存器 (cs,ss等) 和用户栈指针 (esp)。
- 调用
proc_run,它会设置TSS,然后执行irq_iret(ctx),通过一次“假的中断返回”跳转到用户程序。
sys_exec 的实现几乎完全复用了这个流程,只是场景稍有不同:我们不是从内核的初始状态启动程序,而是在一个正在运行的用户程序的系统调用处理流程中,去替换这个用户程序。
实践 #
A. 实现 load_arg 函数
#
这个函数是构建参数栈的核心。
- 操作: 完成
kernel/src/loader.c中的load_arg函数。 - 逻辑步骤:
- 计算参数数量 (
argc):遍历传入的argv数组直到遇到NULL。 - 设置栈顶:
stack_top指向用户栈的最高地址。 - 压入字符串:
- 从最后一个参数字符串开始,倒序遍历。
- 对于每个字符串,先在栈上为它分配空间(
stack_top -= (strlen(str) + 1)),然后用strcpy把它复制到stack_top指向的位置。 - 将这个字符串的地址(也就是当前的
stack_top值)存入一个临时的本地数组argv_va中。
- 对齐栈: 将
stack_top向下对齐到4字节边界。 - 压入
argv数组 (指针数组):- 首先压入
NULL作为结束标记。 - 然后倒序将在
argv_va中保存的字符串地址压入栈中。
- 首先压入
- 压入
_start的参数:- 压入
argv数组的地址(此时的stack_top值)。 - 压入
argc的值。
- 压入
- 压入伪返回地址:
stack_top -= 4。 - 返回: 返回最终的
stack_top值,这就是用户程序启动时的ESP。
- 计算参数数量 (
B. 在 load_user 中调用 load_arg
#
- 操作: 修改
kernel/src/loader.c中的load_user函数。 - 细节: 调用你刚刚实现的
load_arg,并将其返回值赋给ctx->esp。
C. 修改 init_user_and_go 以测试
#
- 操作: 修改
kernel/src/main.c中的init_user_and_go函数。 - 细节: 创建一个字符串数组,例如
char *argv[] = {"echo", "hello", "world", NULL};,然后调用load_user时将程序名"echo"和这个argv数组传递过去。
D. 实现 sys_exec 函数
#
- 操作: 完成
kernel/src/syscall.c中的sys_exec函数。 - 逻辑步骤:
// kernel/src/syscall.c
// sys_exec 的参数 path 和 argv 是由 do_syscall 从中断上下文中解析出来的
int sys_exec(const char *path, char *const argv[]) {
// 1. 获取当前进程的控制块。我们将在它的基础上进行修改。
proc_t *proc = proc_curr();
// 2. 调用 load_user 加载新程序。
// - 第一个参数 pgdir 暂时为 NULL。
// - 第二个参数 proc->ctx 是关键:我们让 load_user 直接覆盖
// 当前进程的上下文。当 load_user 成功返回后,这个 ctx
// 里存储的就不再是旧程序的返回信息,而是新程序的启动信息了。
// - 第三、四个参数是新程序的路径和参数。
if (load_user(NULL, proc->ctx, path, argv) != 0) {
// 3. 处理失败情况。
// 如果 load_user 返回非零值,说明文件不存在或加载失败。
// 我们什么也不用清理,直接返回-1。旧程序会收到这个返回值并继续执行。
return -1;
}
// 4. 处理成功情况。
// 如果 load_user 成功,proc->ctx 已经被完全更新为新程序的初始状态。
// 新程序是对旧程序的夺舍,其内核栈直接使用旧程序的栈。
// 我们现在只需要执行一次“中断返回”,就可以跳转到新程序了。
// 所以执行 irq_iret(proc->ctx)而不是 proc_run(proc)。
// 这个 irq_iret 调用将永远不会返回到 sys_exec 中。
irq_iret(proc->ctx);
// 这行代码理论上永远不会被执行到。
return 0;
}
E. 启动! #
实现了 exec 之后,我们的操作系统就拥有了运行一个真正终端的能力。
- 操作: 修改
kernel/src/main.c中的init_user_and_go函数。 - 细节:
-
创建一个
argv数组,用于启动sh1程序。按照惯例,argv[0]是程序名本身。char *argv[] = {"sh1", NULL}; -
修改
load_user的调用,让它加载"sh1"程序,并传入上面创建的argv。
-
// kernel/src/main.c
void init_user_and_go() {
proc_t *proc = proc_alloc();
assert(proc);
// 准备启动 shell (sh1) 的参数
char *argv[] = {"sh1", NULL};
// 加载 sh1 程序
assert(load_user(NULL, proc->ctx, "sh1", argv) == 0);
// 运行它!
proc_run(proc);
}
总结:终端的运行过程 #
完成以上修改后,重新编译并运行QEMU。你将看到一个熟悉的 $ 提示符。这正是我们自己操作系统上运行的 sh1 终端程序!
你可以尝试与它交互:
-
$ echo hello worldsh1读取你的输入,解析出程序名echo和参数hello,world。sh1调用exec("echo", {"echo", "hello", "world", NULL})。- 我们的内核执行
sys_exec,用echo程序替换掉sh1。 echo程序运行,打印出hello world。echo程序在结束前,会调用exec("sh1", {"sh1", NULL})。- 内核再次执行
sys_exec,用sh1替换掉echo,于是你又回到了终端提示符。
-
$ add 1 2 3 -
$ sleep 100(暂停1秒) -
$ no_such_file(执行一个不存在的程序,exec会失败并返回,sh1会打印错误信息)