
在之前的实验中,我们的操作系统已经具备了中断处理和通过 exec 加载并执行单个程序的能力,形成了一个简易的shell。然而,这个系统本质上是一个“单道批处理系统”(Single-Program System)。它的核心局限在于:任何用户程序都被加载到内存中的同一个预设的物理地址。这导致两个问题:
- 无法并发:内存中同时只能存在一个用户程序,执行完一个才能加载下一个。
- 没有隔离:如果支持多任务,程序A可能会意外或恶意地修改程序B的内存,导致系统崩溃。
为了向现代多任务操作系统迈进,我们必须引入虚拟内存(Virtual Memory)机制。核心目标是为每个进程提供一个独立的、从0开始的、连续的虚拟地址空间,并将这些虚拟地址映射到物理内存中不一定连续的区域。我们将通过实现i386架构下的 分页机制(Paging) 来达成这个目标。
理论:分页机制(Paging) #
0. 内存管理基本概念 #
在深入i386的具体实现之前,我们先复习几个基本概念。
- 虚拟地址空间 (Virtual Address Space): 操作系统为每个进程“虚构”的内存空间。在32位系统中,这个空间的大小是 \(2^{32}\) 字节,即4GB (从
0x00000000到0xFFFFFFFF)。进程中的所有代码和数据都使用虚拟地址。 - 物理地址空间 (Physical Address Space): 这是实际存在于你计算机上的RAM内存条所构成的地址空间。CPU的内存管理单元(MMU)最终必须将虚拟地址转换为物理地址才能存取数据。
- 页 (Page) 和 页框 (Page Frame): 为了便于管理,虚拟和物理地址空间都被划分为固定大小的块。
- 虚拟地址空间中的块称为页 (Virtual Page)。
- 物理地址空间中的块称为页框 (Physical Page Frame)。
- 在x86架构中,一个页/页框的标准大小是 4KB (\(2^{12}\) 字节)。
- 页表 (Page Table): 这是实现地址映射的核心数据结构。它记录了每个虚拟页到哪个物理页框的映射关系。每个进程都有自己独立的页表。
1. 页表的结构 #
页表用什么结构来存储映射关系呢?一个最直观的想法是创建一个巨大的数组作为页表,数组的每个元素对应一个虚拟页,内容是其映射的物理页框地址。我们来计算一下这个数组有多大:
- 一个进程的虚拟地址空间大小: 4GB = \(2^{32}\) B
- 页大小: 4KB = \(2^{12}\) B
- 虚拟页数量: \(2^{32} / 2^{12} = 2^{20}\) 个
- 每个页表项需要4字节来存储物理页框地址和一些标志位。
- 总大小: \(2^{20}\) * 4B = 4MB。
这意味着,为了支持一个进程,操作系统需要开辟一块4MB的连续物理内存(空间大、空间连续性要求高)来存放它的页表。这在物理内存碎片化的情况下几乎是不可能满足的,并且即便进程只用了几个页面,也需要为它分配完整的4MB页表,造成巨大的浪费。
i386的解决方案:两级页表,PDE->PTE #
为了解决上述问题,i386架构将这个4MB的大页表“拆分”成了两级:
- 页目录 (Page Directory, PD): 这是第一级表。它包含1024个页目录项 (Page Directory Entry, PDE)。整个页目录大小为 1024 * 4B = 4KB,正好占用一个物理页框。每个PDE指向一个二级页表。
- 页表 (Page Table, PT): 这是第二级表。每个页表也包含1024个页表项 (Page Table Entry, PTE)。整个页表大小也是 1024 * 4B = 4KB,占用一个物理页框。每个PTE最终指向一个4KB的物理页框。
这样,\(2^{20}\) 个虚拟页的映射关系被组织成:1个页目录 -> 最多1024个页目录项 -> 最多1024*1024个页。这种结构解决了内存占用过大的问题——如果一个进程只使用了少量内存,那么存储页表的空间会极大程度缩小。例如,只映射了8MB的虚拟地址,那么它只需要1个页目录(4KB)和2个页表\(8 * 10^{20} / 10^{12} / 10^{10}\),总共12KB,而不需要完整的4MB的页表结构。大部分PDE可以为空,从而无需为它们分配对应的二级页表。
还有一个好处是,页目录和页表本身可以被存放在物理内存的任何离散的4KB页框中,无需连续。
2. 页表的数据结构:页目录项(PDE)与页表项(PTE) #
在i386中,PDE和PTE的结构几乎完全相同,都是一个32位的整数,其结构如下:
31 12 11 9 6 5 2 1 0
+--------------------------------------+-------+---+-+-+---+-+-+-+
| | | | | | |U|R| |
| PAGE FRAME ADDRESS 31..12 | AVAIL |0 0|D|A|0 0|/|/|P|
| | | | |S|W| |
+--------------------------------------+-------+---+-+-+---+-+-+-+
P - Present: 存在位。如果为1,表示该PTE/PDE有效,其指向的页/页表在物理内存中。如果为0,表示不在内存中,访问它会触发一个Page Fault异常。R/W - Read/Write: 读/写位。如果为1,表示该页可读可写。如果为0,表示只读。U/S - User/Supervisor: 用户/超级用户位。如果为1,表示用户态(Ring 3)的代码可以访问该页。如果为0,则只有内核态(Ring 0)可以访问。00: 保留位,必须为0。A - Accessed: 访问位。当CPU访问该页时,硬件会自动将该位置1。操作系统可以利用它来实现某些页面置换算法。D - Dirty: 脏位(仅用于PTE)。当CPU对该页执行写操作时,硬件会自动将该位置1。这告诉操作系统此页内容已被修改,如果需要换出到磁盘,必须先写回。AVAIL: 可用位,供操作系统使用。PAGE FRAME ADDRESS: 高20位,指向一个物理页框的基地址。由于页框总是4KB对齐的,其物理地址的低12位必然为0,因此这里只需要存储高20位(即页框号)即可。- 在PDE中,它指向一个二级页表(PT)的物理基地址。
- 在PTE中,它指向一个数据/代码页(Page Frame)的物理基地址。
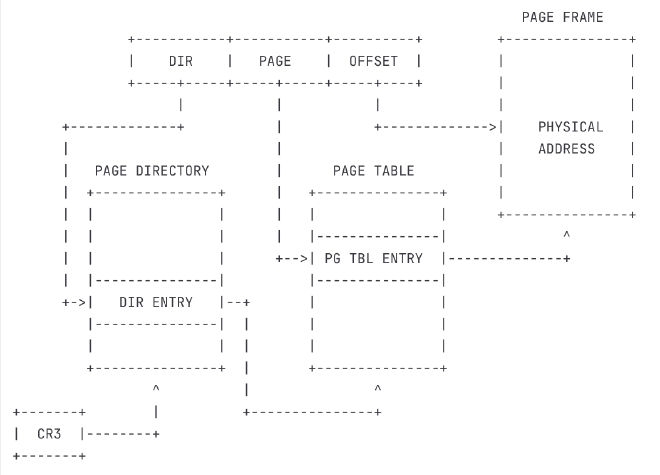
3. 地址转换 #
首先,我们需要复习一下,分页出现之前,逻辑地址是怎么转换成线性地址的。在未开启分页时,线性地址就等于物理地址。分页之后,如何从线性地址转换到物理地址呢?这就是分页机制的核心。
两级页表下线性地址的结构 #
一个32位的线性地址被硬件划分为三个部分,以匹配两级页表结构:
31 22 21 12 11 0
LINEAR +------------+-----------+--------------+
ADDRESS | DIR | PAGE | OFFSET |
+------------+-----------+--------------+
DIR: 高10位,用作在页目录(PD)中的索引。PAGE: 中间10位,用作在页表(PT)中的索引。OFFSET: 低12位,表示在最终找到的4KB物理页框内的偏移量。
硬件进行的地址翻译 #
- 定位页目录: CPU从控制寄存器
CR3中获取当前进程的页目录(PD)的物理基地址。CR3中存储的就是一个页对齐的物理地址。 - 查找PDE: CPU使用线性地址的高10位(
DIR)作为索引,在页目录中找到对应的页目录项(PDE)。地址计算方式为:PDE地址 = CR3中的基地址 + DIR * 4。 - 定位页表: 从该PDE中,CPU提取出高20位的页框地址,这是下一级页表(PT)的物理基地址。
- 查找PTE: CPU使用线性地址的中间10位(
PAGE)作为索引,在刚找到的页表中定位到对应的页表项(PTE)。地址计算方式为:PTE地址 = PDE指向的页表基地址 + PAGE * 4。 - 定位物理页: 从该PTE中,CPU提取出高20位的页框地址,这正是我们最终要访问的数据/代码所在的4KB物理页框的基地址。
- 计算最终物理地址: 将上一步得到的物理页框基地址与线性地址的低12位(
OFFSET)相加,得到最终的物理地址。物理地址 = PTE指向的物理页框基地址 + OFFSET。
重要:权限保护 #
地址转换不仅仅是翻译,更是一个保护的过程。在上述翻译的每一步,硬件都会检查PDE和PTE中的权限位。
下表总结了不同模式下,对内存进行不同操作时,PTE/PDE标志位必须满足的条件:
| 内存操作 | CPU运行状态 | P位要求 | R/W位要求 | U/S位要求 |
|---|---|---|---|---|
| 读 | 内核态 (Ring 0) | 1 | 不做要求 | 不做要求 |
| 写 | 内核态 (Ring 0) | 1 | 1 | 不做要求 |
| 读 | 用户态 (Ring 3) | 1 | 不做要求 | 1 |
| 写 | 用户态 (Ring 3) | 1 | 1 | 1 |
- 权限检查是分层级的。CPU首先检查PDE的权限,再检查PTE的权限。只要有一级不满足,就会立即中止并触发异常。例如,一个用户程序想写入某个地址。即使它对应的PTE的
R/W和U/S位都是1(允许用户写),但如果它所属的PDE的R/W位是0(只读),那么写操作依然会失败。这是一种有效的保护机制,内核可以通过设置PDE来一次性将一大片内存(4MB)区域设置为只读或仅内核访问。 - 任何不满足存在位(P=0)或权限检查的访问,都会导致CPU抛出一个14号中断——页错误异常(Page Fault),将控制权交给操作系统内核来处理。这是实现缺页加载、写时复制等高级内存管理技术的基础。
实践:分页机制的代码实现 #
第一步:构建分页所需要的数据结构 #
为了在代码中清晰地表示页目录、页表以及它们的条目,我们在 kernel/include/x86/memory.h 文件中定义了一系列C结构体和联合体。
页目录项 (PDE) 和 页表项 (PTE) #
我们使用一个union(联合体)来定义PDE(PTE的定义与之类似),这是一种非常巧妙的C语言技巧。
// 定义于 kernel/include/x86/memory.h
typedef union PageDirectoryEntry {
struct {
uint32_t present : 1; // 位 0: Present (P)
uint32_t read_write : 1; // 位 1: Read/Write (R/W)
uint32_t user_supervisor : 1; // 位 2: User/Supervisor (U/S)
uint32_t page_write_through : 1; // 位 3: Page-level write-through
uint32_t page_cache_disable : 1; // 位 4: Page-level cache disable
uint32_t accessed : 1; // 位 5: Accessed (A)
uint32_t : 1; // 位 6: (忽略) 对于PDE是Dirty位,此处保留
uint32_t page_size : 1; // 位 7: Page size (0 for 4KB)
uint32_t : 4; // 位 8-11: (忽略) 可供操作系统使用
uint32_t page_frame : 20; // 位 12-31: 页框物理地址的高20位
};
uint32_t val; // 用于一次性读/写整个32位条目
} PDE;
present : 1这样的语法定义了一个名为present的成员,它只占用1个比特位。编译器会自动处理位的打包和提取,让你无需手动进行位运算。
union允许我们用两种方式看待同一块32位的内存。- 我们可以通过
pde.present、pde.read_write这样的方式,像操作结构体成员一样,去独立地读写某一个标志位。这得益于C语言的**位域(bit-field)**特性(: 1表示该成员只占1位)。 - 我们也可以通过
pde.val,像操作一个普通的uint32_t整数一样,一次性对整个32位条目进行赋值或读取。这在设置一个完整的页表项时非常高效。
- 我们可以通过
页目录 (PD) 和 页表 (PT) #
页目录本质上就是一个包含1024个PDE的数组。页表同理。
// 定义于 kernel/include/x86/memory.h
#define NR_PDE 1024 // 一个页目录中有1024个PDE
// 按 PGSIZE (4096字节) 进行内存对齐
#define PG_ALIGN __attribute((aligned(PGSIZE)))
typedef struct PageDirectory {
PDE pde[NR_PDE] PG_ALIGN;
} PD;
PG_ALIGN:__attribute((aligned(PGSIZE)))是一个给编译器的指令。i386架构硬件要求页目录和页表的物理基地址必须是4KB对齐的(即地址的低12位必须为0)。这个属性可以确保任何时候我们在代码中声明一个PD类型的变量时(如静态变量或全局变量),编译器都会自动保证它的起始地址满足这个对齐要求
第二步:构造操作页表的辅助宏 #
手动进行位运算来处理地址和页表项,繁琐、易错、不易读。为此,框架代码提供了一系列宏来简化操作。理解这些宏的工作原理至关重要。
1. 基础宏 #
-
#define PGSIZE 4096: 定义页面大小为4KB。 -
#define PGMASK PGSIZE - 1): 页面掩码,二进制0x00000FFF。addr & PGMASK可以提取出地址的低12位(页内偏移);addr & ~PGMASK可以将地址向下对齐到最近的4KB边界。 -
#define PAGE_DOWN(addr) (((uint32_t)(addr)) & (~PGMASK)): 将地址向下对齐到最近的页边界。& (~0xFFF)等价于& (0xFFFFF000), 即将低12位置零。例如:0x12345 -> 0x12000 -
#define PAGE_UP(addr) (((uint32_t)(addr) + PGMASK) & (~PGMASK)): 将地址向上对齐到最近的页边界。先加上一个(最大的)小于页大小的数,使得只要地址不是页对齐(即自身为4KB边界)的,其值就会进位到下一个4KB边界,然后再向下取整。例如:0x12001 -> 0x13000, 0x12000 -> 0x12000
2. 地址分解宏 #
这些宏帮助我们从一个32位线性地址中提取出页目录索引、页表索引和页内偏移。
-
#define DIR_SHIFT 22: 页目录索引在地址的第22位开始 -
#define TBL_SHIFT 12: 页表索引在地址的第12位开始 -
#define ADDR2DIR(addr) (((uint32_t)(addr) >> DIR_SHIFT) & 0x3FF)从地址中提取页目录索引 (高10位)。0x3FF是10个1 -
#define ADDR2TBL(addr) ((((uint32_t)(addr) >> TBL_SHIFT)) & 0x3FF)从地址中提取页表索引 (中10位)。 -
#define ADDR2OFF(addr) (((uint32_t)(addr)) & PGMASK): 从地址中提取页内偏移 (低12位)
3. PDE/PTE 构造与转换宏 #
- 构建权限位的三个宏
#define PTE_P 0x001Present (存在位)#define PTE_W 0x002Writeable (可写位)#define PTE_U 0x004User (用户位)
// 构建一个PDE。addr是页表的物理地址,prot是权限位(如PTE_W | PTE_U) // 它会自动将地址向下对齐,并或上权限位和存在位PTE_P
-
#define MAKE_PDE(addr, prot) (PAGE_DOWN(addr) | (prot) | (PTE_P))构建一个PDE。addr是页表的物理地址,prot是权限位;它- 自动将地址向下对齐,保证页表地址合法;
- 或上权限位,正确设置页表的权限;
- 或上存在位,确保页表被标记为有效。
-
#define MAKE_PTE(addr, prot) (PAGE_DOWN(addr) | (prot) | (PTE_P))构建一个PTE。addr是物理页框的物理地址,prot是权限位。逻辑同上。 -
#define PDE2PT(pde) ((PT*)((pde).page_frame << 12)): 从一个PDE中解析出它指向的页表的地址。pde.page_frame是高20位地址,左移12位即可得到4KB对齐的基地址。 -
#define PTE2PG(pte) ((void*)((pte).page_frame << 12)): 从一个PTE中解析出它指向的物理页的虚拟地址
代码模拟地址翻译过程 #
void* va_to_pa(uint32_t va) {
// 1. 从CR3寄存器获取当前页目录(PD)的物理地址。
// get_cr3()是一个内联汇编函数,用于读取CR3。
// 内核中虚拟地址=物理地址(想一想为什么?之后会解释),所以可以直接转换成PD指针。
PD *pgdir = (PD*)PAGE_DOWN(get_cr3());
// 2. 从虚拟地址va中计算出页目录索引。
int pd_index = ADDR2DIR(va);
// 3. 在页目录中找到对应的页目录项(PDE)。
PDE *pde = &(pgdir->pde[pd_index]);
// 在实际情况中,你需要检查pde->present位是否为1。
// 如果为0,说明对应的二级页表不存在,会触发Page Fault。这里我们假设它存在。
// 4. 从PDE中解析出二级页表(PT)的基地址。
PT *pt = (PT*)PTE2PG(*pde);
// 5. 从虚拟地址va中计算出页表索引。
int pt_index = ADDR2TBL(va);
// 6. 在二级页表中找到对应的页表项(PTE)。
PTE *pte = &(pt->pte[pt_index]);
// 同样,实际中需要检查pte->present位。这里假设它存在。
// 7. 从PTE中解析出最终物理页(Page Frame)的基地址。
void *page_base_addr = PTE2PG(*pte);
// 8. 将物理页基地址与页内偏移量相加,得到最终的物理地址。
void *pa = (void*)((uint32_t)page_base_addr | ADDR2OFF(va));
return pa;
}
第三步:初始化内核页目录 #
现在进入实战环节。我们的第一步是在分页机制启动前,为内核本身建立一套页表。目标是建立一个恒等映射 (Identity Mapping),即让虚拟地址V映射到物理地址V。为什么?
操作系统启动时必是有一段时间不是分页的,我们考察一下分页前后的状态:分页开启前一瞬间,CPU处于没有开启分页的保护模式。此时,CPU发出的所有内存地址都是物理地址。内核的代码、全局变量、栈都位于某个物理地址上。指令指针寄存器(EIP)里存的是下一条指令的物理地址。开启分页的瞬间,从下一条指令开始,CPU发出的所有地址都会被MMU(内存管理单元)当作虚拟地址来进行翻译(和os怎么配合的?答案是设置cr3为PD地址,MMU就从这个地址开始查找),那我不仅要问,如果我们的分页机制没有建立恒等的映射,翻译出来的物理地址就不是原来的物理地址了,内核代码、全局变量和栈的地址值都变了,内核还怎么运行下去?
恒等映射可以确保在开启分页后,内核代码(如EIP指令指针)、全局变量和栈(如ESP栈指针)的地址值不需要改变,内核可以无缝地继续运行。
具体操作 #
在kernel/src/vme.c的init_page()函数中,完成以下工作:
- 填充内核的页目录
kpd和一组页表kpt。 - 建立
[0, PHY_MEM)范围内的恒等映射。这意味着虚拟地址0x80000就映射到物理地址0x80000。 - 加载页目录地址到CR3寄存器,并设置CR0寄存器以开启分页。
代码分析 #
在 init_page 函数中,你会看到已经为你准备好的变量:
static PD kpd;: 内核的页目录。static确保它被放在.bss段,初始化为0。static PT kpt[PHY_MEM / PT_SIZE];: 一组页表。PT_SIZE是一个页表能映射的内存大小 (1024个PTE * 4KB/PTE = 4MB)。PHY_MEM(128MB) 是模拟器的总物理内存。- 所以
kpt是一个包含128MB / 4MB = 32个页表的数组(同时PDE也有32条),足以映射全部物理内存。
// 遍历所有我们需要的页表 (对应kpd中的PDE)
for (uint32_t i = 0; i < PHY_MEM / PT_SIZE; i++) {
// 1. 设置kpd中的第i个页目录项(PDE)
// 它应该指向第i个页表(kpt[i])
// 权限是什么?内核需要读和写,所以R/W位应该是1(虽然内核态根本不检查这一位),用户位U/S应该是0
kpd.pde[i].val = MAKE_PTE(&kpt[i], PTE_W);
// 2. 填充kpt[i]这个页表中的1024个页表项(PTE)
for (uint32_t j = 0; j < NR_PTE; j++) {
// i就是pde索引,j就是pte索引,由此算出页表项指向的页对应的虚拟地址
uint32_t va = (i << DIR_SHIFT) | (j << TBL_SHIFT);
// 因为是恒等映射
uint32_t pa = va;
// 使用MAKE_PTE构建PTE,并填入kpt[i]中
kpt[i].pte[j].val = MAKE_PTE(pa, PTE_W);
}
}
在完成映射的建立后,你需要添加Wiki中提到的三行关键代码:
-
kpt[0].pte[0].val = 0;- 目的:这行代码特意取消了对虚拟地址
0x0到0x0FFF(第一个页)的映射。这是一个经典的防御性编程技巧。如果程序中出现了空指针解引用(访问地址0),在没有分页或0x0被映射的情况下,它可能会访问到内存中的合法数据(例如中断向量表),导致难以察觉的奇怪错误。取消映射后,任何对空指针的访问都会立即触发Page Fault异常,让BUG无处遁形,极大地简化了调试。
- 目的:这行代码特意取消了对虚拟地址
-
set_cr3(&kpd);- 目的:将
kpd的物理地址加载到CR3寄存器。CPU的MMU从此知道要去哪里查找页目录。
- 目的:将
-
set_cr0(get_cr0() | CR0_PG);- 目的:读取
CR0寄存器的当前值,并将其最高位(PG, Paging)置1。一旦这一位被设置,分页机制立即生效。CPU处理的每一个内存地址都会经过前面描述的地址翻译流程。
- 目的:读取
第四步:管理堆区内存 #
理论:为什么需要堆区管理? #
在上一部分,我们通过恒等映射将整个物理内存(0 到 PHY_MEM)都映射到了内核的虚拟地址空间中。但是整个内存应该被如何使用呢?
[0, KER_MEM)范围内的内存被内核的静态代码、全局变量和内核栈所占用。[KER_MEM, PHY_MEM)范围内的内存(通常是很大的剩余部分)目前是“闲置”的。
当内核在运行时需要动态申请一块内存来存储数据(例如,为新进程创建PCB、页表,或者开辟缓冲区)时,它就需要从这块“闲置”的区域中拿出一部分来用。这个过程不能是随意的,否则不同的模块可能会同时使用同一块内存,造成数据覆盖和系统崩溃。因此,我们需要一套机制来有条不紊地管理这块区域,明确哪些内存是“已分配”的,哪些是“空闲”的。
这套机制就是内核的堆区管理。我们将实现两个核心函数:
void *kalloc(): 申请一页(4KB)的空闲物理内存,并返回其内核虚拟地址(因为是恒等映射,所以也等于其物理地址)。void kfree(void *ptr): 释放之前通过kalloc申请到的一页内存,使其重新变为“空闲”状态,可以被再次分配。
由于内核中绝大多数的内存申请都是以“页”为单位的(例如分配一个页表、一个内核栈),所以我们的分配器只按页进行分配和回收,这大大简化了实现。
理论:管理策略:free list和侵入式链表 #
要管理哪些页是空闲的,一个非常高效且经典的数据结构就是空闲链表 (Free List)。
因为free代表着里面没有内容,member在链表内时不要进行改查操作,所以我们用最方便的增删机制——“头插头删”:将所有空闲的物理页用一个单向链表串联起来,当需要申请一页时(kalloc),我们就从链表的头部取下一个节点,将其对应的页分配出去;当释放一页时(kfree),我们就将这一页作为一个新节点,插入到链表的头部。这种的操作时间复杂度为 O(1),非常高效。
既然是个链表,那我们就需要链表节点来存储next指针。这些节点存放在哪里呢?像一般的页表一样,考虑用一个结构体,里面既有物理页的地址,又有next指针吗?那岂不是每个节点都要额外占用4字节(32位系统下)来存储指针?如果我们有1000个空闲页,就要额外浪费4KB的内存来存储这些指针,太不划算了。
答案是不需要。我们可以利用空闲页本身的内存空间来存储链表指针!
// 定义一个联合体(而不是结构体)来表示一个物理页
typedef union free_page {
union free_page *next; // 指向下一个空闲页的指针,占用前4个字节
char buf[PGSIZE]; // 仅仅是占位符,表示这整个联合体占用 PGSIZE (4096) 字节
} page_t;
// 指向空闲链表头部的全局指针
page_t *free_page_list;
这里的union至关重要。它告诉编译器,next指针和buf数组共享同一块内存的起始位置。这意味着在写内核代码时,我们可以把一个物理页的地址强制转换为page_t*类型,此时这个页的前4个字节就被当作了一个free_page*类型的指针(即next成员)!
这种将链表所需的指针信息直接“嵌入”到被管理的数据元素本身内部的做法,称为侵入式链表。
- 优点:无需为链表节点额外分配内存,节省空间;实现简单高效。
- 可行性:因为这一页内存当前是空闲的,所以其内容是无意义的。我们可以安全地使用其前4个字节来存储我们的管理信息(
next指针)。当这一页被分配出去后,使用者会覆盖这些数据,但这没关系,因为此时它已经不在空闲链表中了。
free_page_list
|
v
+------------+ +------------+ +------------+
| next ------|----->| next ------|----->| next ------|----> NULL
| | | | | |
| (Page N) | | (Page M) | | (Page K) |
| ... 4092B | | ... 4092B | | ... 4092B |
+------------+ +------------+ +------------+
[KER_MEM+...] [另一个地址] [又一个地址]
实践 #
定义数据结构 #
在 kernel/src/vme.c 文件的开头,定义上述的数据结构和全局变量。
// kernel/src/vme.c
// ... 其他 include ...
// 定义空闲页结构体
typedef union free_page {
union free_page *next;
char buf[PGSIZE];
} page_t;
// 定义全局的空闲链表头指针,初始化为NULL
static page_t *free_page_list = NULL;
// ... 其他代码 ...
初始化空闲链表 #
回到 kernel/src/vme.c 的 init_page() 函数,找到第二个 TODO。你需要在这里将 [KER_MEM, PHY_MEM) 范围内的所有完整页都加入到 free_page_list 中。
// 从 KER_MEM 开始,它是第一个可用的空闲内存地址
// 我们需要确保起始地址是按页对齐的,使用 PAGE_UP 宏
for (uint32_t p = PAGE_UP(KER_MEM); p + PGSIZE <= PHY_MEM; p += PGSIZE) {
// 1. 将当前的物理地址 p 强制转换为 page_t* 指针
page_t* page = (page_t*)p;
// 2. 执行链表的头插法
page->next = free_page_list;
free_page_list = page;
}
实现 kalloc 和 kfree
#
在 kernel/src/vme.c 中找到并实现这两个函数。
// 申请一页物理内存,返回其地址
void* kalloc() {
// 检查链表是否为空
panic_on(free_page_list == NULL, "[vme/kalloc]: out of memory!");
// 头删法:取出链表头的页
page_t* page = free_page_list;
free_page_list = page->next;
// 0!0!0! 避免使用者读到旧的脏数据
memset(page, 0, PGSIZE);
return page;
}
注意这里
kalloc被设计为不可能返回NULL。如果内存耗尽,内核会直接panic。这样方便我们后面处理(不需要那么多assert了)
// 释放一页物理内存,ptr必须是通过kalloc申请的页地址
void kfree(void* ptr) {
// 参数检查:是否为NULL,是否按页对齐
panic_on(ptr == NULL, "[vme/kfree]: trying to free a NULL pointer!");
panic_on(((uintptr_t)ptr % PGSIZE) != 0,
"[vme/kfree]: illegal(unaligned) page address!");
// 头插法
page_t* page = (page_t*)ptr;
// 填充垃圾值,便于调试
memset(page, 0xcc, PGSIZE);
page->next = free_page_list;
free_page_list = page;
}
第五步:为用户空间实现虚拟内存管理 #
内核空间使用[0, PHY_MEM)范围的虚拟地址,并且所有进程共享同一套内核页目录和页表,权限为内核。而用户进程需要自己独立的地址空间,我们约定,用户进程的虚拟地址空间只使用 [PHY_MEM, 4GB) 这个范围。与内核不同,用户态每个进程都必须有自己专属的页目录。
我们接下来的任务就是编写一组函数(API),来封装创建、修改和销毁这些用户页目录的复杂操作。
以下是你需要实现的API函数。它们都应该在kernel/src/vme.c中实现。我们建议你至少实现 vm_alloc、vm_walkpte 和 vm_map,因为它们是后续实验的基础。
注意API中的权限管理,即对
prot的处理!prot一般有5种:0(无效)、1或3(仅内核可读写)、5(内核可读写、用户只读)、7(内核和用户都可读写)
PD *vm_alloc()
#
// 返回一个用户的页目录,并恒等映射[0, PHY_MEM)范围的内存作为内核空间
PD* vm_alloc() {
PD* pgdir = (PD*)kalloc();
// 遍历内核页目录 `kpd` 中负责映射 `[0, PHY_MEM)` 的部分(即前32个PDE)
// 并将它们**原样复制**到新创建的页目录的对应位置。
// 上一周说过的内核栈
for (int i = 0; i < PHY_MEM / PT_SIZE; i++) {
// 这里的prot已经在init_page中被设置为3
pgdir->pde[i].val = kpd.pde[i].val;
}
// 剩下的PDE默认就是0了,因为kalloc返回的内存已经被清零
return pgdir;
}
void vm_teardown(PD* pgdir)() #
// 把`pgdir`这一页目录下的所有页表,和所映射到的所有非内核物理页全部free掉
// 前32个PDE是内核空间的(不是kalloc分配的),不能动
void vm_teardown(PD* pgdir) {
if (pgdir == NULL) {
return;
}
// i从32开始,也就是第33个PDE
// 页目录,页表,页表项都可以用kfree处理
for (int i = PHY_MEM / PT_SIZE; i < NR_PDE; i++) {
PDE* pde = &pgdir->pde[i];
if (pde->present) {
PT* pt = (PT*)PDE2PT(*pde);
for (int j = 0; j < NR_PTE; j++) {
PTE* pte = &pt->pte[j];
if (pte->present) {
void* pa = PTE2PG(*pte);
kfree(pa);
}
}
kfree(pt);
}
}
kfree(pgdir);
}
PTE *vm_walkpte(PD *pgdir, uintptr_t va, int prot)()
#
// 返回pgdir这一页目录下,va对应的PTE指针
// 如果不存在,且prot&1(人话:prot认为存在位为1),则按需创建
// 如果不存在,且!(prot&1),则返回NULL
PTE* vm_walkpte(PD* pgdir, size_t va, int prot) {
// 确保prot只包含P, W, U三位
assert((prot & ~7) == 0);
// 1. 获取页目录索引并找到对应的PDE
uint32_t pd_idx = ADDR2DIR(va);
PDE* pde = &pgdir->pde[pd_idx];
// 2. 检查PDE是否有效
if (!pde->present) {
if (!(prot & PTE_P)) {
return NULL;
}
void* pt_addr = kalloc();
// 设置pde指向的页表地址和权限
pde->val = MAKE_PDE(pt_addr, prot);
} else {
// 确保PDE的权限是其下所有PTE权限的超集
pde->val |= prot;
}
// 4. 获取二级页表(PT)的地址
PT* pt = (PT*)PDE2PT(*pde);
// 5. 获取页表索引并返回对应的PTE指针
uint32_t pt_idx = ADDR2TBL(va);
return &pt->pte[pt_idx];
}
void* vm_walk(PD *pgdir, size_t va, int prot)()
#
// 返回pgdir这一页目录下,va对应的物理地址
void* vm_walk(PD* pgdir, size_t va, int prot) {
// if prot&1 and prot voilation ((pte->val & prot & 7) != prot), call
// vm_pgfault if va is not mapped and !(prot&1), return NULL
PTE* pte = vm_walkpte(pgdir, va, 0);
if (pte == NULL || !pte->present) {
if (prot & PTE_P) {
// vm_pgfault(va, 0);
}
return NULL;
}
if ((pte->val & prot & 7) != (prot & 7)) {
vm_pgfault(va, 1);
return NULL;
}
void* page_addr = PTE2PG(*pte);
return (void*)((uintptr_t)page_addr | ADDR2OFF(va));
}
void vm_map(PD *pgdir, uintptr_t va, size_t len, int prot)
#
// 在`pgdir`下,为一段虚拟地址区间 `[va, va+len)` 建立`prot`权限的映射,并分配物理内存。
void vm_map(PD* pgdir, size_t va, size_t len, int prot) {
// prot至少要有PTE_P,且只有三位
assert(prot & PTE_P);
assert((prot & ~7) == 0);
size_t start = PAGE_DOWN(va);
size_t end = PAGE_UP(va + len);
assert(end >= start);
// 1. 遍历所有需要映射的虚拟页地址
for (size_t current_va = start; current_va < end; current_va += PGSIZE) {
// 2. 找到该虚拟地址对应的PTE指针,如果二级页表不存在则创建
PTE* pte = vm_walkpte(pgdir, current_va, prot);
panic_on(pte == NULL, "[vme/vm_map]: vm_walkpte failed");
if (pte->present) {
pte->val |= prot;
} else {
// 分配一页物理内存
void* pa = kalloc();
pte->val = MAKE_PTE(pa, prot);
}
}
}
void vm_unmap(PD *pgdir, uintptr_t va, size_t len)()
#
// 在`pgdir`这一页目录下,取消`[va, va+len)`这一范围的映射,并且`kfree`掉它们映射的物理页。
void vm_unmap(PD* pgdir, size_t va, size_t len) {
assert(ADDR2OFF(va) == 0);
assert(ADDR2OFF(len) == 0);
if (len == 0) return;
// 1. 遍历所有需要取消映射的虚拟页
for (size_t current_va = va; current_va < va + len; current_va += PGSIZE) {
PTE* pte = vm_walkpte(pgdir, current_va, 0);
if (pte == NULL || !pte->present) {
continue;
}
void* pa = PTE2PG(*pte);
kfree(pa);
pte->val = 0;
}
// 冲刷TLB
if (pgdir == vm_curr()) {
set_cr3(vm_curr());
}
}
第六步:在分页机制上运行用户程序 #
1. 改造程序加载器 (load_elf)
#
1.1 加载引入虚拟地址 #
到目前为止,我们的load_elf函数(位于 kernel/src/loader.c)是将程序直接加载到物理内存中。现在,它必须学会将程序加载到由特定页目录 (pgdir)管理的虚拟地址空间中。
对于ELF文件中的每一个需要加载的程序段(program segment),load_elf必须完成两个核心步骤:
- 映射虚拟内存: 使用我们之前实现的
vm_mapAPI,为该程序段在目标pgdir下映射所需的虚拟地址空间[p_vaddr, p_vaddr + p_memsz)。 - 拷贝程序数据: 将ELF文件中的数据 (
p_filesz字节) 拷贝到刚刚映射好的内存区域。
这里有一个挑战:load_elf函数本身运行在内核的地址空间下(由kpd管理),而它需要操作的是目标用户进程的地址空间(由传入的pgdir管理)。这意味着内核不能直接通过虚拟地址(如p_vaddr)写入用户空间,因为当前的CR3寄存器指向的是kpd。
虽然我们可以通过vm_walk手动将用户的每一个虚拟地址翻译成物理地址再写入,但这非常繁琐。一个更高效、更简洁的技巧是**“临时切换地址空间”**:
- 保存当前上下文: 在加载开始前,用
PD *old_pgdir = vm_curr();保存当前的页目录。 - 切换到目标上下文: 使用
set_cr3(pgdir);将CPU的CR3寄存器切换到目标用户进程的页目录。- 为什么这是安全的? 因为根据我们的
vm_alloc实现,任何新的用户页目录都已经复制了内核的恒等映射。因此,切换后,内核代码本身仍然可以正常执行,不会“跑飞”。
- 为什么这是安全的? 因为根据我们的
- 直接操作虚拟地址: 切换后,MMU硬件会自动使用新的
pgdir进行地址翻译。现在,内核可以直接向p_vaddr这样的虚拟地址写入数据,CPU会自动将它路由到正确的物理页。这大大简化了数据拷贝的逻辑。 - 恢复上下文: 在所有程序段加载完毕后,务必用
set_cr3(old_pgdir);将CR3寄存器切换回原来的内核页目录。
1.2 映射栈空间 #
程序不仅需要代码和数据,还需要一个栈。加载完所有ELF段后,你需要为用户程序分配并映射一个栈空间。
- 虚拟地址: 约定用户栈位于用户空间顶部,即
[USR_MEM - PGSIZE, USR_MEM),也就是[0xbffff000, 0xc0000000)。 - 操作: 调用
vm_map(pgdir, USR_MEM - PGSIZE, PGSIZE, prot)。
1.3 正确设置权限 #
ELF的程序头(ProgramHeader)中有一个p_flags字段,它告诉我们这个段应有的权限:
- 如果
(p_flags & PF_W)不为零,表示该段可写。映射时prot应为PTE_U | PTE_W(用户读/写)。 - 否则,该段为只读。映射时
prot应为PTE_U(用户只读)。 - 用户栈总是可写的,
prot应为PTE_U | PTE_W。
2. 适配进程管理 #
为了让每个进程拥有自己的地址空间,我们需要对进程管理代码进行一系列适配。
proc_t结构体: 在kernel/include/proc.h中,为进程控制块proc_t添加pgdir成员,用于指向该进程的页目录。- 进程创建 (
proc_alloc): 在kernel/src/proc.c的proc_alloc中:- 调用
vm_alloc()为新进程创建一个页目录,并赋值给proc->pgdir。 - 重要:之前所有进程共享一个硬编码的内核栈,这是不安全的。现在,你需要为每个进程独立分配一个内核栈。调用
kalloc()分配一页内存作为proc->kstack。
- 调用
- 进程调度 (
proc_run): 在kernel/src/proc.c的proc_run中,上下文切换现在必须包含地址空间的切换。在irq_iret之前,加入set_cr3(proc->pgdir);。 - 初始进程启动: 在
kernel/src/main.c的init_user_and_go中,调用proc_alloc创建第一个用户进程,然后将proc->pgdir传递给load_user函数。
3. 适配参数加载 (load_arg)
#
load_arg (位于 kernel/src/loader.c) 的任务是将命令行参数拷贝到用户栈上。在分页模型下,我们必须严格区分物理地址和虚拟地址。
- 内核视角 (写): 内核代码操作的是物理地址。它需要知道用户栈顶对应的物理地址才能向其中写入数据。
- 旧代码:
stack_top是一个硬编码的物理地址。 - 新代码: 你需要用
vm_walk(pgdir, USR_MEM - PGSIZE, PTE_W)找到用户栈页对应的物理地址,其顶部就是stack_top。
- 旧代码:
- 用户视角 (读): 用户程序看到和使用的是虚拟地址。因此,压入栈中的所有指针(如指向 “sh1” 字符串的指针)都必须是虚拟地址。
- 旧代码: 直接压入物理地址
stack_top的某个偏移。 - 新代码: 你需要计算出对应的虚拟地址。例如,如果一个字符串被拷贝到了物理地址
p_addr,而p_addr在用户栈页内,那么它对应的虚拟地址就是(USR_MEM - PGSIZE) + ADDR2OFF(p_addr)。
- 旧代码: 直接压入物理地址
4. 适配系统调用 #
sys_getpid: 一个简单的热身。在kernel/src/syscall.c中实现它,只需返回当前进程proc_curr()的pid即可。sys_exec: 这是个关键的系统调用。当一个进程调用exec时,它的内存映像被一个新程序完全替换。- 步骤:
- 调用
vm_alloc()创建一个全新的页目录pd_new。 - 调用
load_user(pd_new, ...)将新程序加载到这个新地址空间中。 - 如果加载成功:
- 用
vm_teardown()释放当前进程旧的页目录和内存。 - 将当前进程的
pgdir指向pd_new。 - 使用
set_cr3(pd_new)立即切换到新的地址空间。 - 由于每个进程有独立的内核栈,别忘了用
set_tss更新TSS,指向当前进程新的kstack。
- 用
- 如果加载失败,则
vm_teardown(pd_new)释放为新程序分配的资源,并返回错误。
- 调用
- 步骤:
5. 调试利器:实现页错误处理器 #
在这个阶段,代码中最常见的bug就是内存访问错误,它们都会以**页错误(Page Fault)**的形式出现。与其让QEMU崩溃,不如我们自己捕获这个异常并打印有用的调试信息。
- 中断号: Page Fault是14号中断 (
EX_PF)。 - 错误信息: CPU会自动将导致错误的虚拟地址存入
CR2寄存器,并将一个描述错误类型的errcode压入内核栈。
- 在
kernel/src/cte.c的irq_handle函数中,添加一个case EX_PF:分支。 - 在该分支中,调用
vm_pgfault(get_cr2(), ctx->errcode);。 vm_pgfault函数(位于vme.c)会打印出CR2(出错地址)和errcode,然后panic。
- 位 0 (P): 1=保护权限错误 (页存在但权限不足), 0=页不存在。
- 位 1 (W): 1=写操作导致错误, 0=读操作导致错误。
- 位 2 (U): 1=错误发生在用户模式, 0=错误发生在内核模式。
例如,errcode = 4 (二进制100) 意味着:用户模式(1)下进行了一次读操作(0),但目标页面不存在(0)。
第七步:实现用户堆区管理 (brk)
#
到目前为止,用户程序的内存布局是静态的。在加载时,操作系统根据ELF文件分配了代码段、数据段和栈。但如果程序在运行时需要一块大小不定的内存(例如,用户输入一个N,程序需要创建一个N个元素的数组),静态内存就无能为力了。
这就是堆 (Heap) 的用武之地。堆是位于数据段之上、栈之下的一块可动态增长和缩减的内存区域。用户程序通过malloc()、free()等库函数来使用堆内存,而这些库函数的底层正是依赖一个叫做 brk 的系统调用来向操作系统申请或归还大块内存。
理论:程序中断点 (Program Break) #
为了管理堆,内核需要为每个进程维护一个指针,这个指针标记了“已分配给进程的数据区的末尾”。这个指针被称为程序中断点 (Program Break)。
让我们回顾一下用户进程的虚拟地址空间布局:
+------------------+ 0xc0000000 (USR_MEM)
| Stack | <--- (grows downward)
| ... |
| |
+------------------+
| |
| (Unmapped Memory)|
| ... |
+------------------+ <--- Program Break (brk)
| Heap | <--- (grows upward)
+------------------+
| .bss (uninit.) |
+------------------+
| .data (init.) |
+------------------+
| .text (code) |
+------------------+ 0x08048000 (approx.)
| ... (Reserved) |
+------------------+ 0x0
Program Break就是上图中堆顶部的那个边界。- 当用户程序调用
malloc申请内存时,C库函数会检查当前堆中是否有足够的空闲空间。如果没有,它就会调用brk系统调用,请求内核向上移动Program Break,从而“圈占”更多的虚拟地址空间。内核响应这个请求,就会使用vm_map为这片新的地址空间分配物理页。 - 当程序调用
free释放大量内存后,C库可能会调用brk,请求内核向下移动Program Break,将不再需要的内存区域归还给操作系统。
初始值: 当一个程序刚被加载时,它的堆是空的。此时,Program Break 指向.bss段的末尾。为了方便按页管理,我们约定初始的Program Break是.bss段末尾地址向上取整到最近的页边界的值。
实践:实现sys_brk调用
#
- 函数原型:
int sys_brk(void *addr); - 功能: 请求内核将当前进程的
Program Break移动到addr指定的新位置。 - 内核实现 (
sys_brk):- 首次调用: 在一个新进程中,内核记录的
brk值是0。当brk首次被调用时,内核知道这是在进行初始化。它会将用户程序传递来的初始brk值(通常是PAGE_UP(end))记录在进程的PCB中。 - 堆增长: 如果
addr指定的新位置高于当前的Program Break,内核就需要为[current_brk, new_brk)这段虚拟地址区间分配物理内存并建立映射。 - 堆收缩: 如果
addr指定的新位置低于当前的Program Break,内核则需要取消[new_brk, current_brk)这段区间的映射,并回收其占用的物理页。
- 首次调用: 在一个新进程中,内核记录的
现在,你需要将上述逻辑转化为代码。
1. 修改进程控制块 (proc_t)
#
每个进程都有自己独立的Program Break。因此,你需要在进程的“身份证”——proc_t结构体中为它添加一个成员变量来记录这个值。
-
文件:
kernel/include/proc.h -
操作: 找到
proc_t结构体的定义,取消brk成员前面的注释。typedef struct proc { // ... PD *pgdir; uintptr_t kstack; uintptr_t brk; // <--- 取消这一行的注释 } proc_t;
2. 实现 sys_brk 函数
#
所有逻辑都将在 kernel/src/syscall.c 的 sys_brk 函数中实现。
int sys_brk(void *addr) {
// TODO: WEEK3-virtual-memory
proc_t * proc = proc_curr();
size_t brk = proc->brk; // rewrite me
size_t new_brk = PAGE_UP(addr); // rewrite me
if (brk == 0) {
proc_curr()->brk = new_brk;
} else if (new_brk > brk) {
vm_map(vm_curr(), brk, new_brk - brk, PTE_P | PTE_U | PTE_W);
proc->brk = new_brk;
} else if (new_brk < brk) {
vm_unmap(vm_curr(), new_brk, brk - new_brk);
proc->brk = new_brk;
}
return 0;
}