
上一次实验我们已经掌握了“信号量”这一强大的同步工具,并用它解决了哲学家就餐和生产者-消费者问题。信号量的使用场景通常隐含了一个前提:参与同步的各个进程能够访问到同一个信号量实例。在我们之前的实现中,父进程在通过fork创建子进程时会继承父进程的信号量(但是信号量引用数要增加),父子进程能通过相同的id访问到相同的信号量实例。但是,如果有些问题需要进程共享信号量之外的数据,就会出现困难——
我们复习一下读者-写者问题。可以写成下面的伪代码(信号量实现的这个解法其实是读者优先的):
/* 信号量与共享变量 */
int readcount = 0; // 记录当前正在读取的读者数量
semaphore mutex = 1; // 用于互斥地修改 readcount
semaphore writeblock = 1; // 用于实现写者对资源的独占访问
/* 读者进程 */
process reader() {
// --- 进入临界区 ---
P(mutex);
readcount++;
if (readcount == 1) { // 第一个读者进入
P(writeblock); // 阻止写者进入
}
V(mutex);
// --- 执行读操作 ---
/* reading the shared resource */
// --- 退出临界区 ---
P(mutex);
readcount--;
if (readcount == 0) { // 最后一个读者离开
V(writeblock); // 允许写者进入
}
V(mutex);
}
/* 写者进程 */
process writer() {
P(writeblock);
// --- 执行写操作 ---
/* writing the shared resource */
V(writeblock);
}
而我们尝试用 C 语言和 fork() 来实现上述逻辑,会立刻遇到一个障碍:int readcount 变量。在我们的操作系统中,当一个进程调用 fork() 创建子进程时,内核会为子进程创建一个独立的地址空间。这意味着内核会复制父进程的页表,并为子进程分配新的物理内存页,父进程和子进程拥有各自独立的物理内存。因此,即使父子进程的代码中都访问同一个名为 readcount 的全局变量(它们的虚拟地址可能相同),这个虚拟地址在父进程的页表中被映射到一个物理地址,而在子进程的页表中被映射到另一个不同的物理地址。
为了解决这个问题,我们需要引入一种新的 IPC 机制:共享内存 (Shared Memory)。我们将通过实现两个新的系统调用 mmap() 和 munmap() 来达成这个目标。
第一步:共享内存 #
什么是进程隔离,什么是共享内存? #
首先,我们需要回顾一下操作系统的基本内存管理原则。在现代操作系统中,每个进程都拥有自己独立的虚拟地址空间。这意味着,尽管进程A和进程B中的代码可能都引用了同一个虚拟地址(例如,全局变量的地址 0x08048000),但操作系统通过各自的页表(Page Table),会将这两个虚拟地址映射到物理内存中两个完全不同的物理地址上。
这种独立性是操作系统提供进程隔离与保护的核心。fork() 系统调用是一个很好的例子:当父进程创建一个子进程时,操作系统会复制父进程的地址空间。这包括复制页表,并为子进程分配新的物理内存页面来存放数据。因此,fork() 之后,父子进程虽然代码和数据看起来一样,但它们对内存的任何修改都互不影响,因为它们操作的是位于不同物理位置的副本。
共享内存机制则特意打破了这种隔离。它允许不同进程的页表将某一段虚拟地址直接映射到同一个物理内存页面。如此一来,任何一个进程通过其虚拟地址修改了这块物理内存的内容,其他所有共享这块内存的进程都能立刻“看到”这个变化,因为它们访问的是同一块物理实体。这提供了一种非常高效的进程间数据交换方式,因为它避免了内核参与的数据拷贝(例如在管道或消息队列中可能发生的情况)。
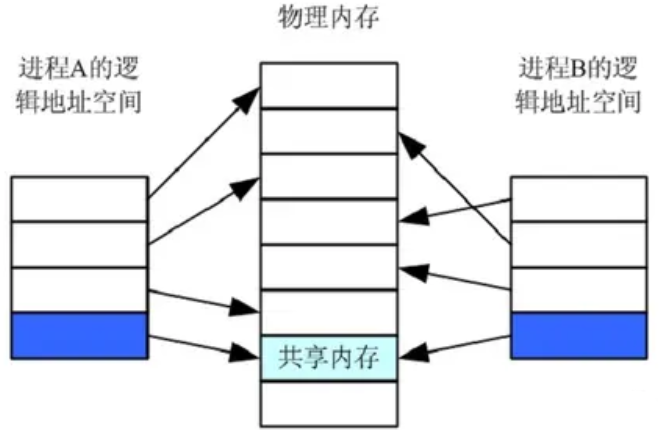
在我们本次的简化实现中,mmap() 的作用就是请求内核分配一块物理内存,并将其映射到调用进程的虚拟地址空间中。而munmap() 则用于解除这一映射关系。
设计思路:物理页的引用计数 #
假设进程A mmap 了一块共享内存,然后 fork 了一个子进程B。现在A和B都映射着同一个物理页。如果此时进程A调用 munmap,我们能直接释放这个物理页吗?显然不能,因为进程B还在使用它。如果释放,进程B后续的访问将导致页错误(Page Fault)甚至系统崩溃。为了解决这个问题,我们需要为每个物理页引入一个“引用计数”机制。其生命周期管理规则如下:
- 分配 (
mmap): 当一个进程首次调用mmap创建一块共享内存时,内核分配一个新的物理页,并将其引用计数初始化为 1。 - 共享 (
fork): 当一个拥有共享内存映射的进程fork子进程时,子进程会继承父进程的页表映射。对于每一个被继承的共享内存页,其对应的物理页引用计数需要 加1。这表示现在多了一个进程(子进程)在使用这个物理页。- 需要注意的是,
fork只会继承调用fork时已经存在的mmap映射。如果在fork之后,父进程又调用了mmap,新创建的这块共享内存是不会被那个已经存在的子进程共享的。
- 需要注意的是,
- 释放 (
munmap或exit): 当一个进程调用munmap解除映射,或者进程退出(exit)时,它所映射的所有共享内存页的引用计数都需要 减1。 - 真正回收: 只有当一个物理页的引用计数减至 0 时,才意味着没有任何进程在使用它了,此时内核才能安全地回收这个物理页,将其放回空闲物理页链表。
这不GC吗
框架代码是怎么实现的? #
为了简化地址管理,我们将共享内存的虚拟地址空间限制在一个特定区域:从 USR_MEM (0xc0000000) 开始,向上扩展。我们将设定一个上界 VIR_MEM (0xf0000000) 以避免地址计算溢出。因此,我们的 mmap 将在这个的范围内寻找一个空闲的虚拟页进行映射。
现在,我们分三步来实现上述机制。
1. 为物理页实现引用计数 #
-
声明引用计数数组: 在
vme.c中,定义一个静态全局数组来存放每个物理页的引用计数。// 类似这样的声明,大小为物理内存总页数 static size_t pm_ref[PHY_MEM / PGSIZE]; -
初始化 (
init_page): 在init_page函数的末尾,将pm_ref数组的所有元素初始化为0。这确保系统启动时所有页面的引用计数都是干净的。 -
修改物理页分配 (
kalloc): 当kalloc成功分配一个物理页面后,在返回物理地址之前,将该物理页对应的pm_ref计数器置为 1。这代表该页面被分配出去,有了一个使用者。 -
修改物理页释放 (
kfree): 这是核心改动。kfree不再立即释放物理页。- 首先,根据传入的物理地址计算出它在
pm_ref数组中的索引,并将对应的引用计数减1。 - 然后,检查该引用计数是否已经变为0。只有当计数为0时,才执行原来释放物理页的逻辑(例如,将其加入空闲链表)。如果大于0,则什么都不做。
2. 实现 mmap 与 munmap 系统调用
#
在有了引用计数支持后,我们可以开始构建上层的系统调用接口。
- 定义地址上界: 在
kernel/include/x86/memory.h中添加#define VIR_MEM 0xf0000000,方便后续使用。 - 实现
sys_mmap:- 寻找空闲虚拟地址: 在当前进程的地址空间中,从
USR_MEM开始,以PGSIZE为步长,向上遍历直到VIR_MEM。检查每个地址对应的页表项(PTE),找到第一个不存在(即未被映射)的虚拟页地址mmap_va。 - 处理空间耗尽: 如果遍历完整个区域都找不到空闲虚拟页,说明共享内存空间已满,
mmap失败,返回NULL。 - 分配与映射:
- 调用
vm_map(),这个函数会自动映射物理地址并将找到的空闲虚拟地址mmap_va映射到物理地址上。 - 成功后,返回
mmap_va。
- 调用
- 寻找空闲虚拟地址: 在当前进程的地址空间中,从
- 实现
sys_munmap:- 只需要调用
vm_unmap()(或类似的页表操作函数) 来处理指定的虚拟地址addr。 vm_unmap应该会负责查找虚拟地址对应的物理地址、在页表中清除映射关系、用kfree()来处理那个物理地址。kfree会自动处理引用计数的减一和按需回收。
- 只需要调用
3: 在 fork 中正确处理共享内存的继承
#
最后一步是确保当进程创建子进程时,共享内存能够被正确地“共享”过去,而不是“复制”。
- 扩展遍历范围:
vm_copycurr函数原本的实现可能只复制了USR_MEM以下的用户空间。你需要扩展它的遍历逻辑,增加一个循环来处理从USR_MEM到VIR_MEM的地址区间。 - 处理共享页: 在这个新的循环中,对于每一个虚拟地址:
- 检查父进程的页表中该地址是否被映射。
- 如果被映射,说明这是一个共享内存页。你需要做以下操作:
a. 获取该页映射的物理地址。
b. 找到该物理地址对应的
pm_ref引用计数,并将其 加1。 c. 在子进程的页表 (pgdir参数) 中,建立一个新的映射:将相同的虚拟地址映射到这个相同的物理地址,并设置与父进程相同的权限。这一步是实现“共享”的关键。 - 如果未被映射,则跳过,继续检查下一个页面。
- 时序问题: 请注意,
fork只会继承调用fork时已经存在的mmap映射。如果在fork之后,父进程又调用了mmap,新创建的这块共享内存是不会被那个已经存在的子进程共享的。你的实现需要自然地体现这一点。
与标准 POSIX mmap 的对比
#
有必要了解我们实现的 mmap 只是一个教学目的的简化版。真正的 POSIX mmap 函数功能要强大得多,其原型为:
void *mmap(void *addr, size_t len, int prot, int flags, int fd, off_t offset);
我们实现的版本,实际上等价于调用 POSIX mmap 并传入了如下参数:
addr:NULL(让内核自动选择映射的虚拟地址)len:PGSIZE(我们只支持映射单个页面大小)prot: 读、写、执行权限 (摆了,直接7)flags:MAP_SHARED | MAP_ANONYMOUSMAP_SHARED:表示映射是共享的,对内存的修改对其他进程可见。这正是我们实现的核心。对应的是MAP_PRIVATE,后者表示映射是私有的,修改不会影响其他进程。MAP_ANONYMOUS(或MAP_ANON):表示这是一个“匿名映射”,它不与任何文件关联,纯粹是内核分配的一块内存。
fd:-1要映射到内存中的文件描述符。(因为是匿名映射,所以没有文件描述符)offset:0文件映射的偏移(没有文件,也就没有文件内偏移)。必须是分页大小的整数倍。
最大的区别在于,POSIX mmap 强大的文件映射功能。它可以将一个文件的一部分直接映射到进程的地址空间,使得读写文件就像读写内存一样方便,这对于处理大文件和实现内存数据库等场景至关重要。而我们本次实验只实现了匿名映射,用于父子进程间的通信。
好的,我们继续进行实验的第二部分。作为你的助教,我将同样为你重构并扩充这份关于“写时拷贝”(Copy-on-Write)的实验手册。
好的,我们继续。这是关于实验第二部分“写时拷贝”(Copy-on-Write)的重构笔记。我将遵循你的要求,保持笔记风格,并深入解释技术细节。
第二步:写时拷贝 (Copy-on-Write) #
什么是写时拷贝?怎么设计? #
在之前的实验中,我们的 fork() 系统调用是“重量级”的:它会完整地复制父进程的整个用户地址空间,为子进程分配全新的物理页面,并逐一拷贝内容。这种做法虽然简单直接,但开销巨大:如果父进程占用了大量内存(例如数百MB),fork() 的瞬间会触发大量的内存分配和数据拷贝,导致进程创建过程缓慢。此外,一个非常经典的Unix编程模式是 fork() 之后立即调用 exec(),后者重新分配内存,资源运行新的程序。在这种场景下,子进程刚被创建,其地址空间的内容就被全新的程序镜像所覆盖。那么,fork() 时 painstakingly 拷贝过来的数据就完全被浪费了。
写时拷贝(Copy-on-Write, COW) 正是解决这一问题的关键优化技术。其核心思想非常简单:将昂贵的页面复制操作推迟到真正需要的时候。在 fork() 时,内核不再为子进程复制物理页面。取而代之的是,它让子进程的页表项(PTE)直接指向父进程的物理页面。为了防止父子进程互相干扰,内核会耍一个“花招”:它将这些共享页面的PTE权限位都设置为只读。这样一来,只要父子进程都只对这些页面进行读取操作,它们就可以一直共享同一份物理内存,相安无事。当其中任何一个进程尝试写入数据时,硬件MMU会发现PTE的写权限位为0,从而触发一个页错误(Page Fault),陷入内核。这个页错误就是关键的“信号”。内核的页错误处理程序会接管,检查这是否是一次COW事件。如果是,它才会为写入方分配一个新的物理页面,将旧页面的内容复制过去,然后更新该进程的PTE,指向新的、可写的页面。至此,“延迟复制”才真正完成。
框架代码实现 #
要实现COW,我们需要对现有的内存管理和异常处理机制进行扩展。
-
pm_ref: 这是我们在上一部分共享内存实验中已经实现的基础。COW机制完美地复用了它。当fork时,我们不再分配新页面,而是让父子进程共享页面,此时我们只需将对应物理页的pm_ref加一即可。 -
vm_pgfault: 这是本次修改的绝对核心。vm_pgfault不再是一个简单的panic函数。它需要变得“智能”,能够区分真正的非法内存访问错误和由COW机制引发的“良性”缺页。 -
PTE: 当一个页面被设置为只读以启用CoW时,我们如何知道它原本是否是可写的?如果一个进程尝试写入一个原本就是只读的页面(例如代码段.text),这应该是一个真正的段错误,而不是一次COW。为了区分这两种情况,我们必须在PTE中找个地方记录下页面原始的写权限。幸运的是,x86的PTE结构中有一些硬件未使用、可供操作系统自定义的比特位。
1. 扩展PTE结构以支持CoW #
我们需要修改PTE的定义,利用一个闲置位来作为我们的“COW标志位”。这个标志位的作用是告诉页错误处理程序:“这个页面被设置为只读是出于COW的目的,它原本的权限是可写的。”
- 修改
PageTableEntry联合体。可以将 占用一个比特位的pad0字段重新命名为cow。 - 接下来,修改
kernel/src/vme.c中的vm_map函数。在vm_map设置页表项时,如果一个页面被映射为可写 (PTE_W被设置),那么我们自定义的cow位也应该被设置为1。这样,cow位就成了页面“逻辑上是否可写”的记录。
2. 在 fork 中实现CoW逻辑
#
现在需要修改 vm_copycurr,让它在复制进程地址空间时应用COW策略。这个函数需要处理两种内存区域。
USR_MEM以上的共享内存区域: 这部分逻辑保持不变。这些页面本来就是为了多进程读写共享而设计的,它们不参与CoW,其read_write权限位应保持原样。USR_MEM以下的进程私有区域: 这是CoW的主战场。对于这个区域的每一个有效页面,你需要修改复制逻辑:- 不再为子进程调用
vm_map分配新物理页和拷贝数据。 - 直接复制父进程的PTE到子进程的页表中。
- 获取该PTE指向的物理地址,并将其对应的
pm_ref引用计数加1。 - 关键一步: 将父进程和子进程中该页面的PTE的
read_write位都清除(设置为0,即只读)。cow位保持不变(如果原始可写,它就应该是1)。
- 不再为子进程调用
3. 在页处理理程序中实现CoW处理 #
这是最复杂的部分。需要将 vm_pgfault 从一个只会报错的函数,改造成一个能够处理COW事件的调度中枢。
-
修改函数签名: 首先,去
kernel/include/vme.h中移除vm_pgfault声明中的__attribute__((noreturn)),因为它现在可能成功处理并返回。 -
分析错误码:
errcode参数包含了页错误的原因。errcode & 2为真,表示这是一次写操作导致的错误。如果不是写错误,那它就不是COW能处理的,直接跳转到bad标签报错。 -
甄别真正的COW场景: 即使是写错误,也可能是真正的段错误。你需要进行一系列检查,排除这些情况:
- 通过
vm_walkpte查找发生错误的虚拟地址va对应的PTE。如果PTE不存在 (pte == NULLor!(*pte & PTE_P)), 说明进程在尝试写入一个根本未映射的地址。这不是COW,goto bad。 - 检查PTE中的
cow位。如果cow位是0,说明这个页面在逻辑上就是只读的(比如代码段)。进程尝试写入,是真正的权限错误。goto bad。
- 通过
-
执行COW操作: 如果通过了上述所有检查,那么我们确定这是一个合法的COW事件。现在需要根据引用计数分情况处理:
pm_ref == 1(优化路径): 检查该物理页的引用计数。如果计数为1,说明只有当前进程在用这个页面。我们无需再分配和拷贝了。直接将PTE的read_write位重新置为1,赋予写权限即可。这个页面就“物归原主”了。pm_ref > 1(标准路径): 如果引用计数大于1,说明还有其他进程在共享这个页面。此时必须执行复制: a. 调用kalloc()分配一页新的物理内存。 b. 使用memcpy()将旧物理页的内容完整地复制到新分配的物理页上。 c. 更新当前进程的PTE:将page_frame字段指向新的物理页地址,并将read_write位置为1。 d. 不要忘记: 将旧物理页的引用计数pm_ref减1,因为当前进程已经“脱离”了对旧页面的共享。
-
刷新TLB: 修改了页表之后,必须刷新快表(TLB)以确保CPU能看到最新的映射关系。在函数的返回路径上调用
set_cr3(vm_curr());。
好的,我们来整理关于同步原语“管程”的实验笔记。我们将从信号量的局限性出发,理解管程的 motivation,然后深入其核心组件——条件变量,并最终落实在具体的编码实现上。
第三步:管程与条件变量 #
从信号量到管程:为何需要更高级的同步抽象? #
信号量、PV操是强大且基础的同步工具,但直接使用它们来构建复杂的并发程序存在一个固有的问题:管理的复杂性与分散性。
当使用信号量时,对共享资源的互斥访问和同步逻辑分散在每一个参与协作的进程代码中。每个进程都需要正确地调用 P() 和 V()。这种分散的责任模型非常脆弱,容易出错,大致的解决方法也很容易想到:安排一个机制负责所有用户程序的同步管理,所有程序通过一层抽象与这个机制交互。这就引入了管程(Monitor) :它是一种更高层次的编程范式,旨在将共享资源(数据)和所有能操作这些资源的过程(代码)封装在一个独立的模块内。
管程有两个核心保证:
- 互斥 (Mutual Exclusion): 管程内可以有多个进程,但在任何时刻,最多只有一个进程可以在管程内部执行代码。这个保证是隐式的,程序员无需手动调用
P()或V()来保护管程内的共享数据。 - 同步 (Synchronization): 如果一个进程在管程内发现它所等待的条件不满足(例如,尝试从空缓冲区中消费数据),它需要一种机制来临时放弃管程的控制权并等待,同时允许其他进程进入管程。当条件可能被满足时,等待的进程需要被唤醒。这个机制就是条件变量
Condition Variable, CV。
理解条件变量的关键在于它的名字:“条件”。它允许进程等待某个特定条件的发生。一个CV总是和一个互斥锁 (Mutex) 配合使用,这个互斥锁就用来实现管程的隐式互斥。
一个条件变量主要提供两个原子操作:
-
wait(cv, mutex): 当一个进程在管程内(即已持有互斥锁mutex)发现条件不满足时,它会调用wait。这个操作会原子地完成两件事:- 释放互斥锁
mutex。 - 将当前进程置于
cv的等待队列上,并使其睡眠。
原子性至关重要。如果先释放锁再睡眠,那么在释放锁和进入睡眠的间隙,另一个进程可能进入管程、改变了条件并发出信号,而这个信号就会被永远错过。因此,释放锁和睡眠必须是一个不可分割的内核操作。
- 释放互斥锁
-
signal(cv): 当一个进程在管程内改变了某个可能满足其他进程等待条件的状态时(例如,向缓冲区添加了数据),它会调用signal。这个操作会从cv的等待队列中唤醒一个正在等待的进程(如果有的话)。signalall(cv)或broadcast(cv): 类似signal,但它会唤醒所有在cv上等待的进程。这在多个进程可能都满足唤醒条件,或者条件判断比较复杂时非常有用。
API设计与实现策略 #
我们的实验将通过一组系统调用来模拟管程的核心机制。
int cv_open(): 创建一个新的条件变量,返回其ID。int cv_close(int cv_id):销毁一个条件变量。int cv_wait(int cv_id, int sem_id): 核心操作。当前进程在cv_id上等待,并原子地处理与互斥锁sem_id的交互。int cv_sig(int cv_id): 唤醒一个在cv_id上等待的进程。int cv_sigall(int cv_id): 唤醒所有在cv_id上等待的进程。
我们不必从零开始构建等待队列和调度逻辑,可以直接复用已有的信号量机制。
- 互斥锁 (Mutex): 这可以直接用一个二值信号量实现。二值信号量只有两个状态(0和1),常用于任务间的同步和互斥访问。
P(mutex)用于进入管程,V(mutex)用于退出。 - 条件变量 (CV): 一个CV的本质就是一个等待队列。这可以用一个初始值为0的信号量来完美模拟。当一个进程需要在CV上等待时,它对这个值为0的信号量执行
P()操作,自然就会被阻塞。当另一个进程要唤醒它时,只需对这个信号量执行V()操作。
4. 编码实现笔记 (Code Task 5) #
-
文件:
kernel/src/syscall.c -
sys_cv_open():- 这个实现非常直接。它的任务是创建一个代表CV的底层实体。根据我们的策略,这等价于打开一个初始值为0的信号量。直接调用你之前实现的
sys_sem_open(0)即可。
- 这个实现非常直接。它的任务是创建一个代表CV的底层实体。根据我们的策略,这等价于打开一个初始值为0的信号量。直接调用你之前实现的
-
sys_cv_close(int cv_id):- 同理,这等价于关闭
cv_id对应的信号量。调用sys_sem_close()。
- 同理,这等价于关闭
-
sys_cv_wait(int cv_id, int sem_id):- 这是最关键的函数,它必须实现
wait的原子性。sem_id是管程的互斥锁,cv_id是条件变量。 - 步骤1:释放互斥锁。调用
V()操作在sem_id上。 - 步骤2:在条件变量上等待。调用
P()操作在cv_id上。这会导致进程阻塞,直到被cv_sig唤醒。 - 步骤3:重新获取互斥锁。当进程从
P(cv_id)醒来后,它必须在返回用户空间之前,重新获得管程的锁。因此,需要再次调用P()操作在sem_id上。这一点至关重要,它保证了进程从wait返回时,它又重新处于管程的互斥保护之下了。
- 这是最关键的函数,它必须实现
-
sys_cv_sig(int cv_id):- 它的任务是唤醒一个在
cv_id上等待的进程。 - 这等价于对
cv_id对应的信号量执行一次V()操作。
- 它的任务是唤醒一个在
-
sys_cv_sigall(int cv_id):- 它的任务是唤醒所有在
cv_id上等待的进程。 - 你需要检查
cv_id对应信号量的等待队列中有多少个进程,然后循环相应次数,每次都执行一次V()操作。
- 它的任务是唤醒所有在
5. 条件变量的经典使用范式 #
直接使用信号量时,我们写 if 判断。但使用条件变量时,一个健壮的模式是必须使用 while 循环来重新检查条件。
P(mutex);
while (condition_is_not_met) { // 必须是 while, 而不是 if
cv_wait(cv, mutex);
}
// 到达这里时, 必定持有 mutex 且 condition_is_met 为真
// ... 在临界区内执行操作,可能会改变其他进程关心的条件 ...
cv_sigall(cv); // 或 cv_sig(cv),唤醒其他可能满足条件的进程
V(mutex);
为什么必须是 while?
因为当一个进程从 cv_wait 醒来时,它仅仅是得到了一个“条件可能已经满足”的提示,而不是一个保证。在它被唤醒和它再次获得互斥锁mutex的这段时间里,可能有其他进程先一步进入管程,并再次改变了条件,使其重新变为不满足。如果使用 if,进程会错误地继续执行。while 循环确保了进程在继续执行前,一定会重新检查条件,确保万无一失。
完成实现后,运行 producer_cv 测试用例。它的行为应该和你之前用信号量实现的生产者-消费者模型完全一致,这会验证你的条件变量实现是正确的。