
在之前的实验中,我们toy os的并发功能已经有了很大进展:通过调度器Scheduler,实现了多个进程的宏观并发执行;通过系统调用fork(),实现了子进程的创建与管理;通过信号量解决了部分同步问题;通过内存映射mmap,实现了进程间的内存共享与通信。
我们知道,进程是操作系统进行资源分配的基本单位。每个进程都拥有独立的地址空间、页表、文件描述符表等一系列系统资源。这套机制在隔离不同程序、保证系统稳定性方面至关重要。然而,尽管进程模型非常成功,但在某些场景下,它的“重量级”特性会带来性能瓶颈。我们通过一个典型的服务器模型来分析其局限性:
- 服务器主进程监听网络端口,等待客户端请求。
- 每当一个新请求到达(例如,压缩一个文件),服务器
fork()一个新的子进程来处理这个请求。 - 子进程完成任务后退出。
首先,fork() 操作并非轻量。操作系统需要为新的子进程复制父进程的地址空间(即使有 CoW 优化,页表的复制仍有开销)、分配全新的内核栈等。当请求频繁时,这种持续的创建和销毁会消耗大量CPU时间和内存。其次,如果多个处理任务需要访问一个临界区(例如,一个内存中的文件缓存池),由于进程地址空间的独立性,你必须依赖我们之前实现的 mmap 或其他IPC机制。这些机制需要内核介入,涉及复杂的同步控制,增加了延迟和实现的复杂度。
为了解决这些问题,操作系统引入了**线程(Thread)**这一概念。
理论 #
复习:什么是线程? #
线程被设计为CPU调度的基本单位,而进程则作为资源分配的基本单位。一个进程可以包含一个或多个线程。它们之间的关系是:
- 资源共享:同一进程内的所有线程共享该进程的绝大部分资源,包括:
- 虚拟地址空间(代码段、数据段、堆)。
- 打开的文件描述符。(未实现)
- 信号处理器。(未实现)
- 资源独享:每个线程为了能够被独立调度和执行,必须拥有自己的一套独占资源:
- 程序计数器 (PC) 和寄存器组:记录线程的执行位置和状态。
- 栈 (Stack):包括用户栈和内核栈。每个线程的函数调用、局部变量都存储在自己的栈中,因此它们可以执行不同的函数,处于不同的调用深度。这是线程能够独立执行代码路径的根本。
通过这种设计,线程模型带来了显著优势:
- 低创建开销:创建一个新线程,内核只需为其分配一个独立的栈和一套寄存器上下文,而无需复制整个地址空间或文件描述符表。这比创建进程快得多。
- 高效的数据共享:由于所有线程共享同一地址空间,它们可以直接读写全局变量或堆上的数据,就像在同一个函数中一样。这使得线程间的通信变得极为简单,但同时也引入了对同步机制(如信号量、互斥锁)的强依赖,以避免数据竞争。
在Linux的设计哲学中,线程被视为一种轻量级进程 (Lightweight Process, LWP)。这意味着内核在数据结构层面并不严格区分进程和线程,而是用同一种结构(在Linux中是 task_struct,在我们的实验中是 proc_t)来描述两者。一个所谓的“进程”,实际上被看作是一个共享特定资源(如地址空间)的 proc_t 数据结构。
为了加深理解,我们用下图总结一个进程和其内部多个线程的资源关系:
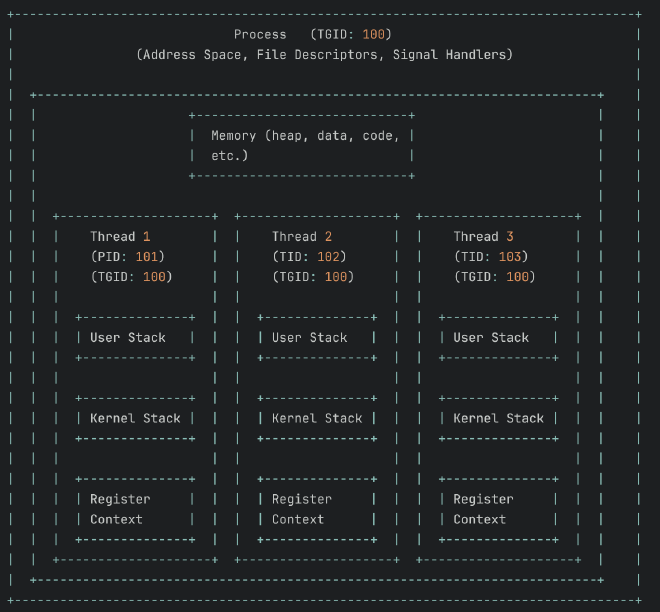
所有proc_t(PID 100, 101, 102)都属于同一个线程组(TGID 100),因此它们会共享同一个页表指针(pagetable),从而共享整个虚拟地址空间。然而,每个proc_t都有自己独立的内核栈(kstack)和中断上下文(trapframe),这是它们能够被独立调度、互不干扰地执行代码的基础。
实现 #
第一步:扩展 PCB 结构以支持线程 #
为了让我们的内核支持线程,我们需要在核心的进程/线程控制块 proc_t 中添加新的成员来管理线程组:
size_t tgid;: 线程组ID (Thread Group ID)。标识线程所属的进程,同一进程的所有线程拥有相同的tgid。我们约定,一个进程的tgid等于其主线程的pid。- 这是进程的唯一标识符。当你说“杀死进程100”,你实际上是想对
tgid为100的整个线程组进行操作。pid则是每个线程(包括主线程)的唯一标识符。通过检查p->pid == p->tgid,我们可以轻易判断一个proc_t描述的是否是主线程。
- 这是进程的唯一标识符。当你说“杀死进程100”,你实际上是想对
int thread_num;: 进程中的线程数量。主要用于管理和调试,记录当前线程组中有多少个活跃线程。struct proc *group_leader;: 一个指针,指向该线程组的主线程的proc_t。即使是主线程自己,它的group_leader也应该指向自身。这提供了一个统一的访问入口,无论你当前持有哪个线程的proc_t,都可以通过p->group_leader找到代表整个进程的那个proc_t。struct proc *thread_group;: 线程组链表指针。用于将同一进程的所有线程的proc_t链接成一个单向链表。- 我们将同一
tgid的所有线程组织成一个单向非循环链表,方便遍历。例如,当需要向进程发送一个信号时,内核可以遍历这个链表,将信号投递给每一个线程。链表的头部是主线程。
- 我们将同一
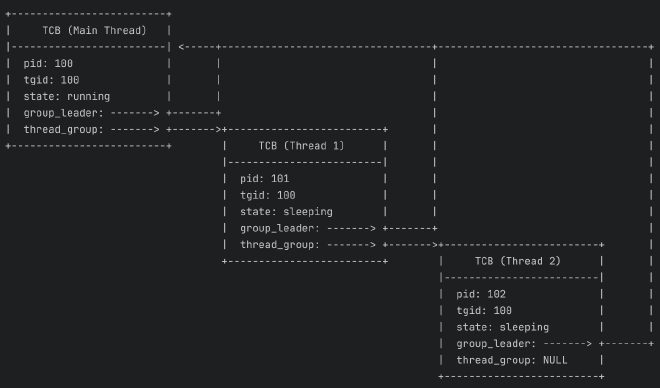
下面的图清晰地展示了这种链式结构。主线程(PID: 100, TGID: 100)是链表的头部。所有线程,包括主线程自身,都通过 group_leader 指回主线程的控制块。
现在,你需要将上述设计应用到实际代码中。你需要修改 proc_t 的定义,并更新负责初始化该结构的函数。当然你还要初始化内核进程pcb[0]和在proc_alloc()中为新进程分配这些新成员的初始值。二者基本相同:
- 设置
p->tgid = p->pid;: 默认自己是主线程,所以tgid等于自己的pid。 - 设置
p->group_leader = p;: 默认自己是领导者。 - 设置
p->thread_num = 1;: 默认线程组里只有自己一个。 - 设置
p->thread_next = NULL;: 默认链表中没有其他成员。
好的,我们继续。非常感谢你提供的明确指示,特别是关于保留 thread_group 变量名,我会严格遵守。
现在,我们来重构和深化实验的第二部分,主题是线程的基础API实现。
第二步:实现线程创建与管理的核心API #
1. 线程创建:clone() 系统调用
#
在标准的类UNIX系统中,fork() 用于创建一个几乎与父进程一模一样的新进程(拥有独立的地址空间),而 clone() 是一个更底层的、功能更强大的API,它允许调用者精细控制子、父执行单元之间共享哪些资源。
在我们的实验中,我们简化这个模型:
fork(): 专门用于创建重量级的进程,拥有独立的地址空间和资源。其现有逻辑保持不变。clone(): 专门用于创建轻量级的线程,新线程将与调用者共享地址空间等核心资源。
我们首先来看用户空间和内核空间的函数原型。
用户空间 #
int clone(int (*entry)(void*), void *stack, void *arg);
entry: 一个函数指针,指向新线程需要执行的函数。stack: 用户为新线程准备的用户栈栈顶地址。由于线程共享地址空间,这个栈通常是通过malloc在堆区动态分配的。arg: 传递给entry函数的参数。- 返回值: 成功时,返回新创建线程的
pid;失败时,返回-1。
内核空间实现 (kernel/src/syscall.c)
#
int sys_clone(int (*entry)(void*), void *stack, void *arg, void (*ret_entry)(void));
- 前三个参数与用户空间API一致。
ret_entry: 这是一个关键的、由用户空间库函数(user/ulib/syscall.c中的clone)传入的“返回垫片”函数地址。
ret_entry 的设计是为了解决一个问题:当线程执行的 entry 函数通过 return 语句结束时,线程应该如何干净地退出?
一个函数执行 return 时,CPU的硬件行为是从栈上弹出返回地址,并跳转到该地址继续执行。对于一个线程来说,它的 entry 函数是被我们“凭空”开始执行的,并没有一个合法的“调用者”返回地址。如果我们不处理,return 将导致程序跳转到一个未知的地址,引发崩溃。
ret_entry 就是我们为 entry 函数手动设置的返回地址。它的工作流程如下:
- 在
sys_clone中,当我们构造新线程的用户栈时,我们会把ret_entry这个函数指针作为entry函数的返回地址压入栈中。 - 当线程的
entry函数执行完毕并return时,CPU会从栈中弹出ret_entry的地址并跳转过去。 ret_entry函数(在我们的实现中是clone_ret_entry)会负责调用thread_exit()系统调用,从而确保线程总是能被内核正确地回收,即使用代码户没有在entry函数末尾显式调用thread_exit()。
这是一种典型的Trampoline(蹦床)机制,确保了控制流总能被导向我们预设的清理路径。
-
分配控制块:
- 调用
proc_alloc()获取一个新的proc_t结构。如果失败(返回NULL),说明系统资源不足,应立即返回-1。
- 调用
-
加入线程组:
- 获取当前线程
p_curr。新线程属于当前线程所在的进程。 - 设置新线程的
tgid为p_curr->tgid。 - 设置新线程的
group_leader指向p_curr->group_leader。 - 将新线程链入线程组的链表。你需要遍历由
p_curr->group_leader开始,通过thread_group指针串联起来的链表,找到最后一个线程,并将新线程挂在它后面。 - 在主线程(
group_leader)的proc_t中,将thread_num加一。 - 按照约定,新创建的线程(非主线程)的
parent指针应设为NULL,因为只有主线程才维持着与父进程的继承关系。
- 获取当前线程
-
共享核心资源:
- 地址空间: 这是线程模型的核心。新线程必须与进程内的其他线程共享同一个地址空间。因此,直接将主线程的页表赋给新线程:
new_thread->pgdir = p_curr->group_leader->pgdir;。不需要为新线程创建或复制页表。 - 其他资源: 文件描述符等资源也是共享的,由于它们存储在主线程的
proc_t中,通过共享页表和group_leader指针,新线程自然就能访问到。
- 地址空间: 这是线程模型的核心。新线程必须与进程内的其他线程共享同一个地址空间。因此,直接将主线程的页表赋给新线程:
-
构建用户栈:
- 用户栈的栈顶由
stack参数指定。 - 你需要在这个栈上构建一个初始的栈帧,以便
entry函数能正确启动。这包括:- 将返回地址
ret_entry压栈。 - 将参数
arg压栈。
- 将返回地址
- 栈帧结构 (从高地址到低地址):
[... user stack space ... | arg | ret_entry_address ]。最终的栈顶指针(esp)应指向ret_entry_address的位置。
- 用户栈的栈顶由
-
构建中断上下文 (
trapframe):- 这是为了让调度器能够将CPU的控制权切换到这个新线程。
tf->eip(指令指针) 应设置为entry函数的地址。tf->esp(栈指针) 应设置为上一步中你构建好的用户栈顶地址。- 其他寄存器的设置(如段寄存器)可以参考
load_user或fork中的实现,确保线程在用户态下运行。
-
准备调度:
- 将新线程的状态设置为
READY。 - 调用
proc_addready()将其放入就绪队列。 - 成功返回新线程的
pid。
- 将新线程的状态设置为
2. 线程退出与进程终结 #
创建了线程,就必须有销毁它们的机制。这里我们需要区分两种退出场景:退出单个线程和退出整个进程。
thread_exit()(对应sys_exit): 只结束调用它的那一个线程。exit()(对应sys_exit_group): 结束整个进程,包括其中的所有线程。
thread_free()
在实现退出逻辑前,我们需要一个辅助函数来回收单个线程的资源。
- 声明: 在
kernel/include/proc.h中声明void thread_free(proc_t *thread);。 - 实现: 在
kernel/src/proc.c中实现。- 这个函数类似于
proc_free,但更轻量。它只释放线程独有的资源。 - 主要工作是:释放线程的内核栈 (
kfree(thread->kstack)) 和清空/回收proc_t控制块本身。 - 特别注意: 绝对不能在这里释放页表 (
pgdir)、文件描述符、信号量等进程共享资源。这些资源的生命周期与进程绑定,由主线程负责管理。
- 这个函数类似于
sys_exit 和 sys_exit_group
-
sys_exit_group(退出整个进程):- 目标: 无论哪个线程调用了
exit(),都必须终结整个进程。 - 实现逻辑:
1. 获取当前线程的主线程
group_leader。 2. 遍历group_leader的thread_group链表。 3. 对于链表中的每一个非主线程的成员,调用thread_free()将其彻底清理。 4. 最后,对主线程group_leader调用proc_makezombie()。这会保留主线程的proc_t,以便其父进程可以通过wait()来回收,同时proc_free()会在最终被调用时释放所有进程级资源(页表、文件等)。
- 目标: 无论哪个线程调用了
-
sys_exit(仅退出当前线程):- 这个函数的行为取决于调用它的是普通线程还是主线程。
- Case 1: 普通线程退出
1. 通知主线程:
proc_curr()->group_leader->thread_num--。 2. 将自身状态变为ZOMBIE,调用proc_makezombie(proc_curr())。这会让主线程有机会清理它。 3. 调用调度器INT(0x81)或sched()放弃CPU,此后再也不会被调度。 - Case 2: 主线程退出
-
主线程是进程资源的管理者,它的退出意味着整个进程的生命周期即将结束。但它不能在还有其他兄弟线程在运行时就直接销毁进程资源。
-
等待机制: 主线程必须等待所有其他线程都退出后,才能进行最后的清理工作。
// 在 sys_exit 中,如果 p_curr 是主线程 while (p_curr->thread_num > 1) { proc_yield(); // 主动让出CPU,等待其他线程运行并退出 } // 循环结束后,说明只剩下主线程自己了 -
最终清理: 当
thread_num降为1时,说明所有其他线程均已退出。此时,主线程的退出逻辑就等同于sys_exit_group:它调用proc_makezombie(p_curr),为整个进程的终结做准备。
-
wait()
wait() 是一个进程间的操作:父进程等待子进程。在我们的模型中,只有主线程才拥有 parent 指针,代表着进程间的父子关系。因此,wait() 的逻辑必须基于主线程来执行。
第三步:协调线程与进程API(fork, exec)
#
exec
#
exec() 系统调用家族(execve, execl, etc.)的核心功能是用一个全新的程序镜像替换当前进程的内存空间、数据和代码。当 exec() 成功返回时,旧的程序已经不复存在,CPU开始执行新程序的第一条指令。
在引入线程后,exec() 的语义需要被精确定义:exec() 是一个作用于整个进程的行为。这意味着,如果一个拥有多个线程的进程中的任何一个线程调用了 exec(),那么整个进程(所有线程)都将被新程序所取代;新程序启动时,将回归到一个纯净的、单线程的状态。
为了实现线程,sys_exec应该这样实现:
- 线程清理: 在加载新程序后,除了一个“幸存”的线程外,所有其他线程都必须被彻底销毁。它们的内核栈、
proc_t结构体都必须被回收。 - 资源重置: 进程的线程相关状态需要被重置。例如,
thread_num必须变回 1,线程链表thread_group必须清空。
exec() 可能由主线程调用,也可能由一个普通的子线程调用。后者会带来一个棘手的技术难题:如果一个非主线程调用了 exec(),该线程正在内核态执行 sys_exec 的代码,这意味着它正在使用自己的内核栈。根据 exec() 的语义,这个调用 exec() 的线程,连同其他所有子线程,最终都应该被销毁,只保留主线程来运行新程序。那么,我们如何销毁一个我们当前正在其上运行的内核栈?直接 kfree() 当前的内核栈会导致内核立即崩溃,因为当前函数的返回地址、局部变量都存储在这里。
我们通过内核栈交换解决这个问题:既然我们无法销毁正在使用的栈,那我们就在销毁调用者之前,将其内核栈与主线程的内核栈进行交换。这样做为什么对?我们分析一下执行流:交换后,执行流(在当前CPU上运行的进程)现在使用的内核栈实际上是原属于主线程的那个;原属于调用者的内核栈,现在被“嫁接”到了主线程的 proc_t 上。接下来,当我们遍历并销毁包括原主线程在内的所有其他线程时,我们实际上销毁的是已经不再被使用的、原属于调用者的内核栈。调用 exec() 的这个线程,虽然其 proc_t 会被保留下来,但它在逻辑上已经“化身”为主线程,承载了整个进程的未来。
// 伪代码,在 sys_exec 中
proc_t *p_curr = proc_curr(); // 当前调用 exec 的线程
proc_t *leader = p_curr->group_leader;
if (p_curr != leader) {
// 如果调用者不是主线程
void* temp_kstack = p_curr->kstack;
p_curr->kstack = leader->kstack;
leader->kstack = temp_kstack;
// ... 可能还需要交换其他与执行上下文相关的状态 ...
}
1.3 sys_exec 实现步骤
-
获取进程代表: 首先,获取当前线程的主线程
group_leader。所有进程级的操作都将围绕它进行。 -
加载新程序: 调用
load_user()加载新的可执行文件。如果失败,立即返回错误。一旦成功,就不能回头了。 -
处理调用者身份 (内核栈交换):
- 判断当前线程
p_curr是否是主线程 (p_curr == group_leader)。 - 如果不是,执行上述的“内核栈交换”逻辑。此时,
p_curr将在逻辑上取代group_leader成为幸存者。我们将继续在p_curr的proc_t上构建新程序的状态,而旧的group_leader的proc_t将在稍后被销毁。为了简化后续逻辑,在交换栈之后,可以将p_curr的内容和group_leader的内容进行一次彻底的交换,确保后续的操作都统一在group_leader的proc_t上进行,而将换出内容的p_curr标记为待销毁。
- 判断当前线程
-
销毁多余线程:
- 遍历由
group_leader开始的thread_group链表。 - 对于链表中的每一个线程,如果它不是那个将要幸存下来的线程(即,执行完栈交换后的
group_leader),就调用thread_free()彻底销毁它。
- 遍历由
-
切换页表与状态重置:
- 关键顺序: 先切换到新程序的页表 (
set_pgdir(new_pgdir)),然后再销毁旧的页表 (pgdir_free(old_pgdir))。顺序绝不能错。 - 重置幸存下来的主线程的线程状态:
leader->thread_num = 1;leader->thread_group = NULL;
- 关键顺序: 先切换到新程序的页表 (
-
启动新程序:
- 像原始的
sys_exec一样,构建好新的中断上下文(trapframe),设置好eip和esp。 - 调用
proc_run()开始执行新程序。
- 像原始的
2. 线程与 fork():进程的“克隆”
#
fork() 系统调用创建一个与父进程几乎一模一样的子进程。在多线程环境下,POSIX标准规定了它的行为:调用 fork() 的线程所在的整个进程被复制,但在子进程中,只有一个线程存在,即那个调用了 fork() 的线程的副本。
2.1 实现 proc_copycurr
fork() 的核心内核逻辑位于 proc_copycurr 函数(kernel/src/proc.c)。我们的任务是确保它正确地复制一个(可能多线程的)进程,并生成一个合法的单线程子进程。
设计原则: fork 是一个进程级别的复制。无论哪个线程发起了调用,我们复制的都应该是整个进程的状态。
任务笔记 (proc_copycurr):
-
获取进程资源源: 在函数开始,获取当前线程的主线程
proc_t *leader = proc_curr()->group_leader;。后续所有资源的复制,都应以leader为源。 -
分配新进程: 调用
proc_alloc()为子进程分配一个新的proc_t。根据我们之前的设计,这个新分配的proc_t默认就是一个主线程,thread_num为1,这正好符合fork的要求。 -
复制进程级资源:
- 地址空间: 调用
uvm_copy(leader->pgdir, ...)来复制父进程的完整地址空间。源页表必须是leader->pgdir。 - 文件描述符: 复制
leader->ofile数组。 - 当前工作目录: 复制
leader->cwd。 - 父子关系: 设置新进程的
parent指针为leader。
- 地址空间: 调用
-
复制调用线程的上下文:
- 子进程的执行将从
fork()返回处开始。为了实现这一点,需要精确复制调用线程的执行上下文。 - 将
proc_curr()->tf(当前调用线程的中断上下文)复制到新进程的tf中。 - 特别地,要设置新进程的
eax寄存器(在中断上下文中)为0,这样fork()在子进程中就会返回0。
- 子进程的执行将从
3. 统一资源管理:以信号量为例 #
在之前的实验中,我们引入了信号量等同步原语。这些是典型的进程级资源。一个进程中的所有线程都应该能访问到同一组信号量。如果资源管理不统一,可能会导致一个线程创建的信号量,另一个线程却无法使用。
设计原则: 任何对进程级资源的操作,都必须通过主线程的 proc_t 进行。
任务笔记 (信号量相关系统调用):
- 目标文件:
kernel/src/syscall.c - 需要修改的函数:
sys_sem_open,sys_sem_p,sys_sem_v,sys_sem_close。 - 修改方法: 在这些函数的实现中,当你需要访问或修改进程的信号量列表时,将所有对
proc_curr()的引用,替换为对proc_curr()->group_leader的引用。
代码示例 (概念性):
// 原来的代码可能像这样:
int sys_sem_p(sem_t *sem) {
// ...
// 在 proc_curr() 的信号量列表中查找 sem ...
// ...
}
// 修改后的逻辑应该是:
int sys_sem_p(sem_t *sem) {
proc_t *leader = proc_curr()->group_leader;
// ...
// 在 leader 的信号量列表中查找 sem ...
// ...
}
第四步:线程级同步与生命周期管理 #
到目前为止,我们已经可以创建和退出线程。但是,我们还缺少一个关键机制:线程间的协作与生命周期管理。
- 协作 (Synchronization): 在很多并行计算场景中,主线程需要分发任务给多个工作线程,并等待它们全部完成后,才能收集并处理最终结果。这就是
join的核心作用:它是一个同步点,允许一个线程阻塞自己,直到另一个线程执行完毕。 - 生命周期 (Lifecycle Management): 并非所有线程都需要被等待。在一个网络服务器中,主线程为每个连接创建一个工作线程后,可能就再也不关心这个工作线程的后续状态了。它只需要工作线程在完成后能自动清理自己,不造成资源泄漏。这就是
detach的作用:它将线程标记为“独立”,生命周期与创建者脱钩,结束后由系统自动回收。
2. 设计与实现:扩展 proc_t 以支持 Join/Detach
#
为了实现这两种模式,我们需要在 proc_t 中添加状态标志和一个同步原语。
扩展 proc_t 结构体 (kernel/include/proc.h):
// in kernel/include/proc.h
typedef struct proc {
// ... 已有成员保持不变 ...
// === WEEK7: Join & Detach 成员 ===
// 标志位:此线程是否可以被 join。
// 1 (默认): 可以被 join。
// 0: 不能被 join (已被 detach 或已被另一个线程 join)。
int joinable;
// 标志位:此线程是否已与创建者分离。
// 0 (默认): 未分离,退出后需要被 joiner 或 parent 回收。
// 1: 已分离,退出后由内核自动回收。
int detached;
// 同步原语:用于阻塞 joiner 线程。
// 初始值为 0。当 joiner 调用 P(wait) 时会立即阻塞。
// 当此线程退出时,会调用 V(signal) 来唤醒 joiner。
sem_t join_sem;
} proc_t;
任务笔记 (初始化):
- 文件:
kernel/include/proc.h:- 在
proc_t结构体中添加joinable,detached, 和join_sem三个成员。
- 在
- 文件:
kernel/src/proc.c:- 在
init_proc和proc_alloc函数中,为这些新成员设置正确的初始值:p->joinable = 1;// 默认可加入p->detached = 0;// 默认不分离sem_init(&p->join_sem, 0);// 初始化信号量,值为0
- 在
3. 实现 detach:线程的独立宣言
#
detach 是一个单向操作。一旦一个线程被分离,它就再也不能被 join,并且它的资源将由系统在它终止时自动回收。
sys_detach 的逻辑很简单:找到目标线程,并修改其状态标志。
任务笔记 (detach):
- 辅助函数
thread_detach:- 声明: 在
kernel/include/proc.h中声明int thread_detach(int tid);。 - 实现: 在
kernel/src/proc.c中实现此函数。- 它接收一个线程ID
tid。 - 遍历进程/线程控制块数组,找到
pid等于tid的proc_t。 - 如果找到,设置
proc->detached = 1和proc->joinable = 0。 - 返回0表示成功,-1表示未找到该线程。
- 它接收一个线程ID
- 声明: 在
- 系统调用
sys_detach:- 文件:
kernel/src/syscall.c sys_detach函数体只需调用thread_detach(tid)并返回其结果即可。
- 文件:
3.2 回收机制:内核成为最终回收者
一个 detached 的线程或一个父进程已退出的孤儿进程,由谁来清理它们的 ZOMBIE 状态并回收资源?答案是内核本身(通常由 PID 为 0 或 1 的初始进程代表)。我们需要建立一个机制,将这些“无人看管”的进程/线程过继给内核。
任务笔记 (内核回收):
-
辅助函数
proc_set_kernel_parent:- 声明: 在
kernel/include/proc.h中声明void proc_set_kernel_parent(proc_t *proc);。 - 实现: 在
kernel/src/proc.c中实现。- 函数接收一个
proc_t指针。 - 将其父进程指针
proc->parent指向内核进程的proc_t。 - 增加内核进程的子进程计数
kernel->child_num++。
- 函数接收一个
- 声明: 在
-
修改
proc_makezombie:- 文件:
kernel/src/proc.c - 在
proc_makezombie中,当一个进程变为僵尸时,检查其子进程是否存在。如果存在,则调用proc_set_kernel_parent(proc)将其过继给内核。
- 文件:
-
修改
sys_exit(支持 detach):- 文件:
kernel/src/syscall.c - 在
sys_exit中,当一个非主线程退出时,检查if (p_curr->detached == 1)。 - 如果为真:
- 从线程组链表中移除自己: 这一步至关重要,防止其他线程(如
exec或kill)再访问到这个即将被销毁的线程。你需要遍历p_curr->group_leader的thread_group链表,找到当前线程的前一个节点,并将其thread_group指针指向当前线程的下一个节点。 - 过继给内核: 调用
proc_set_kernel_parent(p_curr)。 - 变为僵尸: 调用
proc_makezombie(p_curr),它现在是一个等待内核回收的僵尸线程。
- 从线程组链表中移除自己: 这一步至关重要,防止其他线程(如
- 文件:
-
内核的回收循环:
- 文件:
kernel/src/main.c - 在
init_user_and_go函数末尾的while(1)循环中,实现内核的“垃圾回收”逻辑。 - 这个循环不断地调用
proc_findzombie(kernel)来查找是否有过继给它的子进程/线程变成了僵尸。 - 如果找到了一个僵尸子嗣
proc_child:- 判断它是一个进程还是线程。一个简单的判断方法是检查
proc_child->tgid == proc_child->pid。如果是主线程(代表进程),调用proc_free(proc_child)。 - 如果是普通线程,调用
thread_free(proc_child)。 - 回收后,递减内核的子进程计数
kernel->child_num--。
- 判断它是一个进程还是线程。一个简单的判断方法是检查
- 如果没有找到僵尸,就调用
proc_yield()让出CPU,避免忙等待。
- 文件:
4. 实现 kill:强制终止进程
#
在我们的简化模型中,kill 用于终止一个完整的进程(即一个线程组)。
任务笔记 (kill):
-
辅助函数
pid2proc:- 声明: 在
kernel/include/proc.h中声明proc_t *pid2proc(int pid);。 - 实现: 在
kernel/src/proc.c中实现。它遍历全局proc数组,返回pid匹配的proc_t指针,找不到则返回NULL。
- 声明: 在
-
系统调用
sys_kill(kernel/src/syscall.c):- 使用
pid2proc(pid)找到目标进程的proc_t。 - 验证:
- 检查返回的指针是否为
NULL。 - 检查是否为主线程 (
target->pid == target->tgid)。kill的对象是进程,所以必须从主线程入手。 - 如果验证失败,返回 -1。
- 检查返回的指针是否为
- 执行:
- 遍历目标进程的
thread_group链表,对每一个非主线程调用thread_free()进行立即清理。 - 对主线程
target调用proc_makezombie(target),并将其退出码exit_code设置为 9 (SIGKILL 的传统退出码)。
- 遍历目标进程的
- 调度: 如果被杀死的进程就是当前正在运行的进程 (
target == proc_curr()->group_leader),则必须调用INT(0x81)或sched()放弃CPU,因为当前进程已死。 - 返回 0 表示成功。
- 使用
5. 实现 join:等待与结果回收
#
join 是 detach 的对立面,它通过信号量实现了一个优雅的阻塞等待机制。
任务笔记 (join):
-
修改
proc_makezombie(kernel/src/proc.c):- 这是
join机制的“唤醒”部分。 - 在
proc_makezombie(proc)的末尾,无条件地对该线程自身的join_sem执行V操作:sem_v(&proc->join_sem);。 - 这样,无论是否有线程在
join它,这个信号都会被发出。如果有线程正在等待,它将被唤醒;如果没有,信号量的值会从0变为1,下一个(也是唯一一个)尝试join的线程会直接通过而不会阻塞。
- 这是
-
系统调用
sys_join(kernel/src/syscall.c):- 获取当前线程
p_curr和目标线程p_target = pid2proc(tid)。 - 验证:
- 自己不能
join自己 (p_curr == p_target)。 - 目标线程必须存在 (
p_target != NULL)。 - 目标线程必须是
joinable(p_target->joinable == 1)。 - 如果任何检查失败,返回 Linux 错误码
ESRCH(值为3)。
- 自己不能
- 执行:
- 锁定 Join 权:
p_target->joinable = 0;。这一步是原子性的保障,确保只有一个线程能成功join目标。 - 等待: 调用
sem_p(&p_target->join_sem);。当前线程将在此处阻塞,直到p_target退出并调用proc_makezombie。 - 获取返回值: 唤醒后,如果用户传入的
retval指针不为NULL,则将目标线程的退出码拷贝过去:*( (void**)retval ) = (void*)p_target->exit_code;。
- 锁定 Join 权:
- 返回: 返回 0 表示
join成功。
- 获取当前线程
完成以上所有步骤后,你的操作系统将拥有一个功能相对完善的线程系统,支持创建、退出、同步等待 (join) 和独立运行 (detach),并能正确处理与 exec、fork 和 kill 等核心进程API的交互。这标志着你的内核在并发处理能力上迈上了一个重要的新台阶。