
关系,关系模式,关系数据库 #
关系 #
一些数学上的概念的回忆,和在数据库系统内的含义
DomainCartesian ProductRelation: \(R_n\)- \(R\): 关系名
- \(n\): 关系的目/度
Attribute属性: 每一列的名字,比如学号、分数… 属性数=目数
Tuple元组: 集合中的一个元素Component分量:元素中的一个值
码 #
候选码 #
- 若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选码。
- 简单情况:候选码只包含一个属性。
- 最极端情况:关系模式的所有属性组是候选码,称为全码(All-key)。
主码 #
若一个关系有多个候选码,则选定其中一个为主码。
主属性与非主属性 #
- 候选码的所有目的属性属性称为主属性(Prime Attribute)。
- 不包含在任何候选码中的属性称为非主属性(Non-Prime Attribute)或非码属性(Non-key Attribute)。
关系的类别 #
1. 基本关系(基本表或基表) #
- 定义:实际存在的表,是实际存储数据的逻辑表示。
- 例子:
-
学生表(
Students):学号 姓名 年龄 性别 系名 202001 张三 20 男 计算机科学 202002 李四 21 女 数学 202003 王五 22 男 物理 -
课程表(
Courses):课程号 课程名 学分 C 001 数据库 3 C 002 高等数学 4 C 003 英语 2
-
2. 查询表 #
- 定义:查询结果对应的表。
- 例子:
-
查询“计算机科学系的学生”:
学号 姓名 年龄 性别 系名 202001 张三 20 男 计算机科学 -
查询“学分大于 3 的课程”:
课程号 课程名 学分 C 002 高等数学 4
-
3. 视图表 #
- 定义:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据。
- 例子:
-
创建一个视图“计算机科学系学生选课情况”:
CREATE VIEW CS_Students_Courses AS SELECT Students.学号, Students.姓名, Courses.课程名 FROM Students, Courses WHERE Students.系名 = '计算机科学';- 查询视图:
学号 姓名 课程名 202001 张三 数据库
- 查询视图:
-
基本关系的性质 #
1. 列是同质的(Homogeneous) #
- 每一列中的分量(即单元格中的值)是同一类型的数据,来自同一个域。
- 例子:在“学生表”中,“年龄”列的所有值都是整数类型,来自“年龄”这一数据域。
2. 不同的列可出自同一个域 #
- 虽然每列的数据类型相同,但它们代表不同的属性。
- 例子:在“学生表”中,“年龄”列和“学分”列都来自整数域,但分别代表学生的年龄和课程学分。
3. 每一列称为一个属性 #
- 属性是关系模型中列的术语,代表某种特征或数据项。
- 例子:在“学生表”中,“姓名”、“年龄”、“性别”等都是属性。
4. 不同的属性要给予不同的属性名 #
- 不能有两个列都叫“姓名”,必须分别命名为“中文姓名”和“英文姓名”(if needed)。
5. 行、列的顺序无所谓 #
- 将“学生表”中的“姓名”列和“年龄”列对调,表的内容和含义不变。
- 将“学生表”中的第一行和第二行对调,表的内容和含义不变。
6. 任意两个元组的候选码不能相同 #
- 在“学生表”中,“学号”是候选码,每个学生的学号必须唯一。
7. 分量必须取原子值 #
- 每个分量(单元格中的值)必须是不可再分的最小数据单位(例如一个整数或字符串)。
- 例子:在“学生表”中,“姓名”列的值必须是单个名字,不能是一个名字列表。
关系模式 #
1. 定义 #
- 关系模式是“型”,关系是“值”。关系模式是对关系的描述。
- 内容包括:
- 元组集合的结构
- 属性构成
- 属性来自的域
- 属性与域之间的映射关系
- 完整性约束条件
- 元组集合的结构
2. 关系模式的形式化表示 #
关系模式可以形式化地表示为:\(R(U, D, DOM, F)\)
- \(R\):关系名
- \(U\):组成该关系的属性名集合
- \(D\):\(U\) 中属性所来自的域
- \(DOM\):属性向域的映射集合
- \(F\):属性间数据的依赖关系集合
- 简化表示:
- 关系模式通常可以简记为 \(R(U)\) 或 \(R(A_1, A_2, \dots, A_n)\)。
- \(R\):关系名。
- \(A_1, A_2, \dots, A_n\):属性名。
- 域名及属性向域的映射通常直接说明为属性的类型和长度。
- 关系模式通常可以简记为 \(R(U)\) 或 \(R(A_1, A_2, \dots, A_n)\)。
3. 关系模式与关系的区别 #
- 关系模式:对关系的描述,是静态的、稳定的。
- 关系:关系模式在某一时刻的状态或内容,是动态的、随时间不断变化的。
- 说明:
- 关系模式和关系在日常讨论中常笼统称为“关系”,需通过上下文加以区别。
关系数据库 #
- 定义:在一个给定的应用领域中,所有关系的集合构成一个关系数据库。
- 关系数据库的“型”与“值”
- 型:关系数据库模式,是对关系数据库的描述。
- 值:关系模式在某一时刻对应的关系的集合,通常称为关系数据库。
关系的完整性 #
关系间的引用 #
- 定义:在关系模型中,实体及实体间的联系都用关系描述,自然存在关系间的引用。
- 例子:
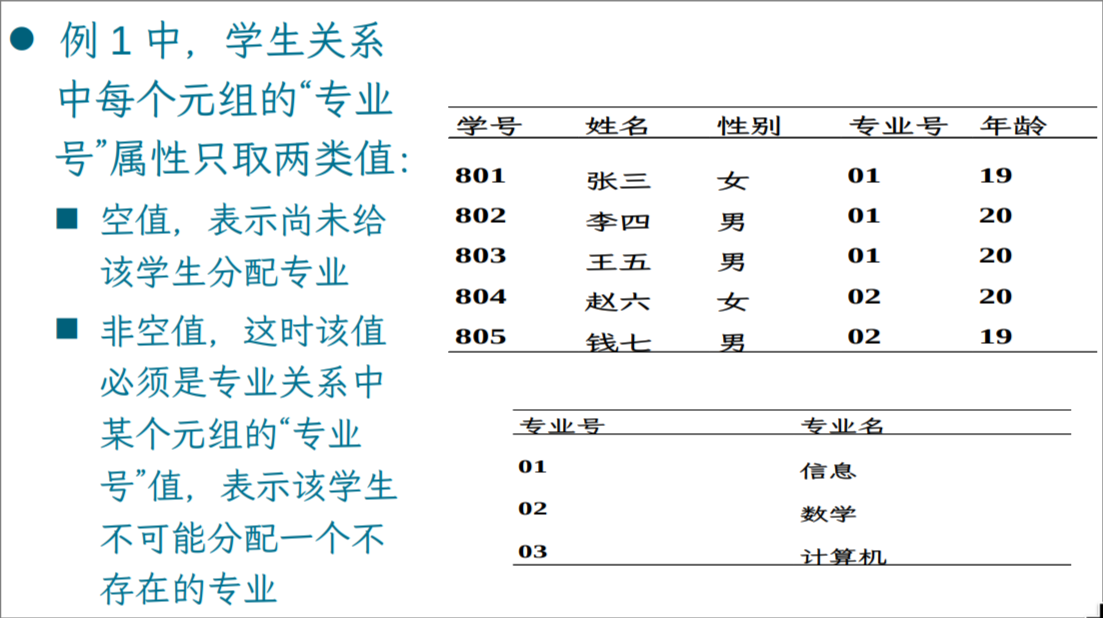
- 学生与专业:
- 学生(学号,姓名,性别,专业号,年龄)
- 专业(专业号,专业名)
- 学生关系引用了专业关系的主码“专业号”。
- 学生、课程与选修:
- 学生(学号,姓名,性别,专业号,年龄)
- 课程(课程号,课程名,学分)
- 选修(学号,课程号,成绩)
- 选修关系引用了学生关系的主码“学号”和课程关系的主码“课程号”。
- 学生内部的领导联系:
- 学生(学号,姓名,性别,专业号,年龄,班长【指的是这个学生所在班级的班长】)
- 学生关系引用自身的主码“学号”来表示班长关系。
- 学生与专业:
外码 #
定义 #
- 设 \(F\) 是基本关系 \(R\) 的一个或一组属性,但不是关系 \(R\) 的码。如果 \(F\) 与基本关系 \(S\) 的主码 \(K_S\) 相对应,则称 \(F\) 是 \(R\) 的外码(Foreign Key), 在这种情况下:
- 基本关系 \(R\) 被称作参照关系(Referencing Relation)
- 基本关系 \(S\) 被称作被参照关系(Referenced Relation)或目标关系(Target Relation):。
- 说明:
- 关系 \(R\) 和 \(S\) 不一定是不同的关系。
- 目标关系 \(S\) 的主码 \(K_S\) 和参照关系的外码 \(F\) 必须定义在同一个(或一组)域上。
- 外码并不一定要与相应的主码同名。当外码与相应的主码属于不同关系时,通常取相同的名字以便于识别。
例子 #
-
学生与专业:
- 学生关系:
学生(学号,姓名,性别,专业号,年龄)
其中,“专业号”是学生关系的外码。 - 专业关系:
专业(专业号,专业名)
其中,“专业号”是专业关系的主码。 专业关系是被参照关系,学生关系是参照关系。
- 学生关系:
-
选修关系:
- 选修关系:
选修(学号,课程号,成绩)
其中,“学号”、“课程号”(之一,不是合起来)是选修关系的外码。 - 学生关系:
学生(学号,姓名,性别,专业号,年龄)
其中,“学号”是学生关系的主码。 - 课程关系:
课程(课程号,课程名,学分)
其中,“课程号”是课程关系的主码。 学生关系和课程关系是被参照关系,选修关系是参照关系。
- 选修关系:
-
学生内部的领导联系:
- 学生关系:
学生(学号,姓名,性别,专业号,年龄,班长)
其中,“班长”是外码,引用了学生关系自身的主码“学号”。 - 学生关系既是参照关系,也是被参照关系。

- 学生关系:
关系的三类完整性约束 #
1. 实体完整性 Entity Integrity
#
若属性 A 是基本关系 R 的主属性,则属性 A 不能取空值(表示“不知道”、“不存在”或“无意义”的值)。
- 例子:
- 关系模式:
选修(学号,课程号,成绩) - 主码为“学号、课程号”,这两个属性均不能取空值
- 关系模式:
- 实体完整性规则是针对基本关系而言的。一个基本表通常对应现实世界的一个实体集。
- 现实世界中的实体是可区分的,即它们具有某种唯一性标识。
- 关系模型中以主码作为唯一性标识。
- 主码中的属性即主属性不能取空值。
- 主属性取空值,就说明存在某个不可标识的实体,即存在不可区分的实体,这与第 2 点相矛盾,因此这个规则称为实体完整性。
2. 参照完整性 #
- 若属性(或属性组)\(F\) 是基本关系 \(R\) 的外码,它与基本关系 S 的主码 \(K_S\) 相对应(基本关系 \(R\) 和 \(S\) 不一定是不同的关系),则对于 \(R\) 中每个元组在 \(F\) 上的值必须为下面两种情况之一
- 取空值(\(F\) 的每个属性值均为空值),代表 \(R\) 中的这个条目目前还不需要这个属性
- 等于 \(S\) 中某个元组的主码值,代表这个条目的属性必须要是有意义的(在 \(S\) 中存在)
当然如果 \(F\) 也是 \(R\) 的主码,那就不能取空值了,只能是第二种情况。
用户定义的完整性 #
- 针对某一具体关系数据库的约束条件,反映某一具体应用所涉及的数据必须满足的语义要求。
- 关系模型应提供定义和检验这类完整性的机制,以便用统一的系统的方法处理它们,而不需由应用程序承担这一功能。
示例:课程(课程号,课程名,学分)
- “课程号”属性必须取唯一值。
- 非主属性“课程名”也不能取空值。
- “学分”属性只能取值 \({1, 2, 3, 4}\)。
关系操作与关系代数 #
关系代数 #
operand是关系,计算结果也是关系- 关系是集合,所以关系代数是集合的操作
operand有两类- 集合运算符:只从行的角度进行,行很行操作产生新的行
- 专门的关系运算符:不仅涉及行,还涉及列
-

运算必须要有意义。
使用的记号 #
规定只使用关系模式的结构 中的两样东西:关系名 和 属性名元组,也就是 $$ R(A_1, A_2, \ldots, A_n) $$ 这个关系模式中:
-
关系: \(R\) 表示一个关系实例。
-
元组: \(t \in R\) 表示 t 是 R 的一个元组
-
分量:\(t[A_i]\) 表示元组 t 中属于属性 \(A_i\) 的一个分量
-
属性列/属性组:设 \(A={A_{i1}, A_{i2}, \ldots, A_{ik}}\), 其中的每一个元素都是 R 的属性,则 \(A\) 是属性列或属性组, \(\overline{A}\) 表示所有属性去掉 A 后的剩余属性组
-
连接:
- \(t_r \in R\),\(t_s \in S\),\(\overset{\frown}{t_r t_s}\) 称为元组的连接。
- \(\overset{\frown}{t_r t_s}\) 是一个 n + m 列的元组,前 n 个分量为 R 中的一个 n 元组,后 m 个分量为 S 中的一个 m 元组。
-
象集: 给定一个关系 R(X,Z),X 和 Z 为属性组。
- 当 \(t[X] = x\) 时,x 在 R 中的象集(Images Set)为:
- \(Z_x = {t[Z] \mid t \in R, t[X] = x}\)
- 它表示 R 中属性组 X 上值为 x 的诸元组在 Z 上分量的集合。
-

- 当 \(t[X] = x\) 时,x 在 R 中的象集(Images Set)为:
关系操作 #
1. 并 #
\(R \cup S\)
- 两个关系目数必须同
- 每目属性相同,对应的属性应取自同一个域
- 仍为 n 目关系,由属于 R或属于 S 的元组组成

2. 差 #
- 和 并 一样,目数、属性有要求,不然运算没有意义
- 仍为 n 目关系,由属于 R 而不属于 S 的所有元组组成

3. 交 Intersection
#
- 和前面一样,…
- 仍为 n 目关系,由既属于 R 又属于 S 的元组组成
-

4. 笛卡尔积 #
严格地讲应该是广义的 (Extended) 笛卡尔积


5. 选择 #
-
在关系 R 中选择满足给定条件的诸元组: $$ \sigma_F(R) = {t \mid t \in R \land F(t) = \text{true}} $$
-
F:选择条件,是一个逻辑表达式,取值为“真”或“假”。
-
基本形式为:\(X_1
\thetaY_1\),其中:- \(\theta\) 表示比较运算符,可以是 \(>\),\(\geq\),\(<\),\(\leq\),\(=\) 或 \(\neq\)。
-
在基本的选择条件上可以进一步进行逻辑运算(与、或、非)。
-
选择运算是从关系 R 中选取使逻辑表达式 F 为真的元组,是从行的角度进行的运算.

6. 投影 #
- 从关系 R 中选择若干属性列 组成新的关系: $$ \pi_A(R) = { t[A] \mid t \in R } $$
- A:R 中的属性列。
- 投影操作主要是从列的角度进行运算。
- 投影之后不仅取消了原关系中的某些列,而且还可能取消某些元组(避免重复行)。
7. 连接 #
连接(Join)也称为 θ连接。
连接运算的含义 #
从两个关系的笛卡尔积中选取属性间满足一定条件的元组: $$ R \bowtie_{AθB} S = { \overset{\frown}{t_r t_s} \mid t_r \in R \land t_s \in S \land t_r[A] \theta t_s[B] } $$
- A 和 B:分别为 R 和 S 上度数相等且可比的属性组。
- θ:比较运算符。
连接运算从 R 和 S 的广义笛卡尔积 \(R \times S\) 中选取 R 关系在 A 属性组上的值与 S 关系在 B 属性组上的值满足比较关系 \(theta\) 的元组。
等值连接(Equijoin) #
当 θ 为“=”的连接运算称为等值连接。从关系 R 与 S 的广义笛卡尔积中选取 A、B 属性值相等的那些元组,即: $$ R \bowtie S = { \overset{\frown}{t_r t_s} \mid t_r \in R \land t_s \in S \land t_r[A] = t_s[B] } $$
自然连接(Natural Join) #
一种特殊的等值连接。
-
条件:
- 两个关系中进行比较的分量必须是相同的属性组。
- 在结果中把重复的属性列去掉。
-
自然连接的含义:
- R 和 S 具有相同的属性组 B: $$ R \bowtie S = { t_r \overset{\frown}{t_s}[U-B] \mid t_r \in R \land t_s \in S \land t_r[B] = t_s[B] } $$
一般的连接操作从行的角度进行运算。 自然连接需要取消重复列,因此是同时从行和列的角度进行运算。




外连接 #
悬浮元组(Dangling tuple) #
在两个关系 R 和 S 进行自然连接时,关系 R 中某些元组可能在 S 中不存在公共属性上值相等的元组,从而导致这些元组在操作时被舍弃。这些被舍弃的元组称为悬浮元组。 如上面例子中的 (a2, b4, 12)
外连接(Outer Join) #
如果在结果关系中保留悬浮元组,并在其他属性上填充空值(Null),这种操作外连接。
-
左外连接 (LEFT OUTER JOIN 或 LEFT JOIN)
- 只保留左边关系 R 中的悬浮元组。
-
右外连接 (RIGHT OUTER JOIN 或 RIGHT JOIN)
- 只保留右边关系 S 中的悬浮元组。
-

-

8. 除运算(Division) #
给定关系 \(R (X, Y)\) 和 \(S (Y, Z)\),其中 X、Y、Z 为属性组。
-
R 中的 Y 与 S 中的 Y 可以有不同的属性名,但必须出自相同的域集。
-
R 与 S 的除运算得到一个新的关系 \(P (X)\),P 是 R 中满足下列条件的元组在 X 属性列上的投影:
- 元组在 X 上的分量值 x 的象集 \(Y_x\) 包含 S 在 Y 上投影的集合,记作: $$ R \div S = { t_r[X] \mid t_r \in R \land \pi_Y(S) \subseteq Y_x } $$ 其中,\(Y_x\) 是 x 在 R 中的象集,且 \(x = t_r[X]\)。
-

-
